DRBDユーザーズガイド バージョン8.4版
はじめにお読みください
本書はDistributed Replicated Block Device (DRBD)を利用するための完全なリファレンスガイドです。同時にハンドブックとしても活用できるように編集してあります。
本書はDRBDプロジェクトのスポンサーである LINBIT がそのコミュニティ向けに作成しています。そしてコミュニティにとって有益であることを願って無償で公開しています。本書はDRBDのリリースに合わせて継続的に更新しています。DRBDの新しいリリースと同時に、その新機能の説明を追加する予定です。オンラインHTML版は http://www.drbd.org/users-guide/ で公開しています。
| このガイドはDRBD 8.4.0以降をご使用のユーザを対象にしています。DRBD 8.4より前のバージョンを使用する場合は、旧版のガイド http://www.drbd.org/users-guide-8.3/ をご利用ください。 |
本書に対する改善提案や誤りの指摘は DRBD関連メーリングリスト へお寄せください。
本書は次の構成になっています。
-
DRBDの紹介 ではDRBDの基本的な機能を扱います。LinuxのI/OスタックにおけるDRBDの位置付け、DRBDの基本コンセプトなど、基礎となる事項を取り扱います。また、DRBDのもっとも重要な機能について検討を加えます。
-
DRBDのコンパイル、インストールおよび設定 ではソースからのDRBDのビルド方法、コンパイル済みのパッケージからのインストール方法、またクラスタシステムでのDRBDの運用方法の概要について説明します。
-
DRBDの使い方 ではDRBDの管理方法、DRBDリソースの設定や修正方法、一般的なトラブルシューティングを説明します。
-
DRBDとアプリケーションの組み合わせ ではストレージのレプリケーションの追加やアプリケーションの高可用性のためDRBDを活用する方法を説明します。Pacemakerクラスタ管理システムとの組み合わせだけでなく、LVMとの高度な組み合わせ、GFSとの組み合わせ、Xenによる仮想環境の可用性向上についても触れます。
-
DRBDパフォーマンスの最適化 ではDRBD設定によりパフォーマンスを向上させるための方法について説明します。
-
DRBDをさらに詳しく知る ではDRBDの内部構造を説明します。読者に有益と思われる他の情報リソースについても紹介します。
-
付録:
-
新しい変更点 は DRBD の以前のリリースと比較した DRBD 8.4 の変更点の概要です。
-
DRBDトレーニングやサポートサービスにご興味のある方は [email protected] にお問い合せください。
DRBDの紹介
1. DRBDの基礎
Distributed Replicated Block Device (DRBD)は、ストレージのレプリケーション(複製)のためのソフトウェアで、シェアードナッシングを実現します。DRBDはサーバ間でブロックデバイス(ハードディスク、パーティション、論理ボリュームなど)の内容をミラーします。
DRBDによるミラーは、次の特徴を持ちます。
-
リアルタイムレプリケーション 上位アプリケーションがデバイスのデータを書き換えると、そのデータをリアルタイムでレプリケートします。
-
アプリケーションから透過的 アプリケーションは、データが複数のホスト上に格納されていることを意識する必要はありません。
-
同期 および 非同期 の両方に対応 同期的に動作している場合、すべてのホストのディスクへの書き込みが完了した後で、アプリケーションは完了通知を受け取ります。非同期的に動作している場合は、ローカルディスクへの書き込みが完了したときに、アプリケーションは完了通知を受け取ります。この場合、他のホストへの書き込みは後で行われます。
1.1. カーネルモジュール
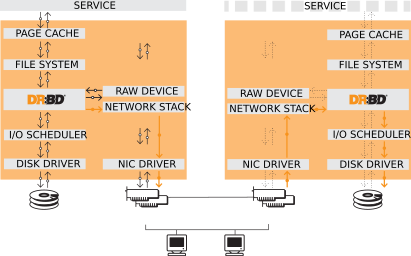
DRBDのコア機能はLinuxのカーネルモジュールとして実装されています。OSのI/Oスタックの一番底に近い場所でDRBDは仮想的なブロックデバイスを作ります。このために、DRBDは非常に柔軟で応用範囲が広く、さまざまなアプリケーションの可用性を高めるために利用できます。
その定義とLinuxカーネルアーキテクチャとの関連にもとづき、DRBDは上位レイヤに関して一切関知しません。このため、DRBDは上位レイヤに対して何らかの機能を付与できません。たとえば、DRBDはファイルシステムの故障を検出できません。またext3やXFSなどのファイルシステムに対してアクティブ-アクティブクラスタ機能を追加することもできません。
1.2. ユーザ空間の管理ツール
DRBDにはカーネルモジュールと通信を行う管理ツールがいくつか用意されています。これらのツールを使って、DRBDリソースを設定して管理できます。
drbdadmDRBDプログラム群における高レベル管理ツールです。このコマンドは、DRBDの制御に必要なすべてのパラメータを /etc/drbd.conf
から読み込み、 drbdsetup および drbdmeta のフロントエンドとして動作します。 drbdadm には -d
オプションで起動する dry-run モードがあり、実際にコマンドを実行することなく、 drbdsetup や drbdmeta のどちらが
drbdadm を呼び出すのかを表示します。
drbdsetupカーネルにロードされたDRBDモジュールを設定します。 drbdsetup ではすべてのパラメータをコマンドラインで指定する必要があります。
drbdadm と drbdsetup が分離していると、柔軟性が高くなります。ほとんどのユーザにとって、 drbdsetup
を使うことはほとんどないでしょう。
drbdmetaDRBDメタデータの作成、ダンプ、リストアなどを行うコマンドです。 drbdsetup と同様、ほとんどのユーザにとって、 drbdmeta
を使うことはほとんどないでしょう。
1.3. リソース
DRBDでは、レプリケートするデータセットに関するさまざまな属性を総称して、リソースと呼びます。リソースは、以下の要素で構成されます。
個々のリソースを区別するために、ホワイトスペース以外のUS-ASCII文字で表される任意の名前を与えることができます。
どのリソースも、共通のレプリケーションストリームを共有する複数の ボリューム
の1つからなる、レプリケーショングループです。DRBDは、リソース内のすべてのボリューム間で書き込みの忠実性が保証されます。ボリュームは 0
から番号付けされ、1つのリソースにおいて、最大で65,535ボリュームまで可能です。ボリュームにはレプリケートされたデータセットが含まれ、DRBD内部で使用するメタデータのセットも含まれます。
drbdadm コマンドでは、リソース内のボリュームを、リソース名とボリューム名を<resource>/<volume>のように記述して指定します。
DRBDが管理する仮想的なブロックデバイスです。DRBDが管理する仮想的なブロックデバイスで、147のメジャー番号を持ち、minor番号は0から順次割り振られます。各DRBDデバイスは、リソース内の1つのボリュームに該当します。関連付けられたブロックデバイスは通常
/dev/drbdX の形式になり、 X
はデバイスのminor番号です。DRBDは、ブロックデバイス名をユーザが定義することもできます。その場合は、ブロックデバイス名を drbd_
で始まるようにしてください。
| 初期のバージョンのDRBDは、NBDのデバイスメジャー番号43を勝手に使っていました。47という番号は、DRBDデバイスメジャー番号として、http://www.lanana.org/docs/device-list/[LANANA-registered]に正式に登録されています。 |
コネクションは、レプリケートされるデータセットを共有する、2つのホスト間の通信リンクです。現時点では、各リソースは2つのホストとこれらのホスト間の1つの接続にのみ関与します。ほとんどの場合、
resource と connection という用語は同じ意味で使われます。
drbdadm では、コネクションはリソース名で指定されます。
1.4. リソースのロール(役割)
DRBDのすべてのリソースは、プライマリまたはセカンダリのどちらかのロール(役割)を持っています。
| 「プライマリ」と「セカンダリ」という用語は適当に選んだものではないことを理解してください。DRBD開発者は意図的に「アクティブ」と「パッシブ」という用語を避けました。プライマリとセカンダリは、ストレージの可用性に関する概念です。一方アクティブとパッシブはアプリケーションの可用性に関わる概念です。ハイアベイラビリティクラスタ環境では、一般的にアクティブノードのDRBDはプライマリになりますが、これが例外のないルールだということではありません。 |
-
プライマリロールのDRBDデバイスでは、データの読み込みと書き込みが制約なく行えます。この状態のストレージに対して、ファイルシステムを作成したりマウントでき、ブロックデバイスに対する下位デバイスI/OやダイレクトI/Oすら可能です。
-
セカンダリロールのDRBDデバイスは、対向するノードでのすべてのデータの更新を受け取りますが、自ノードのアプリケーションからのアクセスは、読み込みと書き込みの両方とも一切受け付けません。読み込みすら受け付けない理由は、キャッシュの透過性を保証するためです。もしもセカンダリリソースが自ノードからのアクセスを受け付けると、この保証ができなくなります。
リソースのロールは、もちろん手動で切り替えできる他に、クラスタ管理アプリケーションの何らかのアルゴリズムによって自動で切り替えられます。セカンダリからプライマリへの切り替えを昇格と呼びます。一方プライマリからセダンダリの切り替えは降格と呼びます。
2. DRBDの機能
本章ではDRBDの有用な機能とその背景にある情報も紹介します。ほとんどのユーザにとって非常に重要な機能もありますが、特定の利用目的に対して重要な機能もあります。これらの機能を使うために必要な設定方法については、「一般的な管理作業」および「トラブルシューティングとエラーからの回復」を参照してください。
2.1. シングルプライマリモード
シングルプライマリモードでは、個々のリソースは、任意の時点でクラスタメンバのどれか1台のみプライマリになれます。どれか1台のクラスタノードのみがデータを更新できることが保証されるため、従来の一般的なファイルシステム(ext3、ext4、XFSなど)を操作するのに最適な処理モードと言えます。
一般的なハイアベイラビリティクラスタ(フェイルオーバタイプ)を実現する場合、DRBDをシングルプライマリモードで設定してください。
2.2. デュアルプライマリモード
デュアルプライマリモードでは、すべてのリソースが任意の時点で両方のノード上でプライマリロールになれます。両方のノードから同一のデータに同時にアクセスできるため、分散ロックマネージャを持つ共有クラスタファイルシステムの利用がこのモードに必須です。利用できるファイルシステムにはGFSおよびOCFS2があります。
2つのノード経由でのデータへの同時アクセスが必要なクラスタシステムの負荷分散をはかりたい場合、デュアルプライマリモードが適しています。このモードはデフォルトでは無効になっており、DRBD設定ファイルで明示的に有効にする必要があります。
特定のリソースに対して有効にする方法については、デュアルプライマリモードを有効にするを参照してください。
2.3. レプリケーションのモード
DRBDは3種類のレプリケーションモードをサポートしています。
非同期レプリケーションプロトコル。プライマリノードでのディスクへの書き込みは、自機のディスクに書き込んだ上でレプリケーションパケットを自機のTCP送信バッファに送った時点で、完了したと判断されます。システムクラッシュなどの強制的なフェイルオーバが起こると、データを紛失する可能性があります。クラッシュが原因となったフェイルオーバが起こった場合、待機系ノードのデータは整合性があると判断されますが、クラッシュ直前のアップデート内容が反映されない可能性があります。プロトコルAは、遠隔地へのレプリケーションに最も適しています。DRBD Proxyと組み合わせて使用すると、効果的なディザスタリカバリソリューションとなります。詳しくはDRBD Proxyによる遠距離レプリケーションを参照してください。
メモリ同期(半非同期)レプリケーションプロトコル。プライマリノードでのディスクへの書き込みは、自機のディスクに書き込んだ上でレプリケーションパケットが他機に届いた時点で、完了したと判断されます。通常、システムクラッシュなどの強制的なフェイルオーバでのデータ紛失は起こりません。しかし、両ノードに同時に電源障害が起こり、プライマリノードのストレージに復旧不可能な障害が起きると、プライマリ側にのみ書き込まれたデータを失う可能性があります。
同期レプリケーションプロトコル。プライマリノードでのディスクへの書き込みは、両ノードのディスクへの書き込みが終わった時点で完了したと判断されます。このため、どちらかのノードでデータを失っても、系全体としてのデータ紛失には直結しません。当然ながら、このプロトコルを採用した場合であっても、両ノードまたはそのストレージサブシステムに復旧できない障害が同時に起こると、データは失われます。
このような特質にもとづき、もっとも一般的に使われているプロトコルはCです。
レプリケーションプロトコルを選択するときに考慮しなければならない要因が2つあります。データ保護とレイテンシ(待ち時間)です。一方で、レプリケーションプロトコルの選択はスループットにはほとんど影響しません。
レプリケーションプロトコルの設定例については、リソースの設定を参照してください。
2.4. 複数の転送プロトコル
DRBDのレプリケーションと同期フレームワークのソケットレイヤは、複数のトランスポートプロトコルをサポートします。
標準的かつDRBDのデフォルトのプロトコルです。IPv4が有効なすべてのシステムで利用できます。
レプリケーションと同期用のTCPソケットの設定においては、IPv6もネットワークプロトコルとして使用できます。アドレシング方法が違うだけで、動作上もパフォーマンス上もIPv4と変わりはありません。
SDPは、InfiniBandなどのRDMAに対応するBSD形式ソケットです。最新のディストリビューションでは、SDPはOFEDスタックのの一部として利用できます。SDPはIPv4形式のアドレシングに使用します。インフィニバンドを内部接続に利用すると、SDPによる高スループット、低レイテンシのDRBDレプリケーションネットワークを実現することができます。
スーパーソケットはTCP/IPスタック部分と置き換え可能なソケット実装で、モノリシック、高効率、RDMA対応などの特徴を持っています。きわめてレイテンシが低いレプリケーションを実現できるプロトコルとして、DRBDはSuperSocketsをサポートしています。現在のところ、SuperSocketsはDolphin Interconnect Solutionsが販売するハードウェアの上でのみ利用できます。
2.5. 効率的なデータ同期
同期ならびに再同期は、レプリケーションとは区別されます。レプリケーションは、プライマリノードでのデータの書き込みに伴って実施されますが、同期はこれとは無関係です。同期はデバイス全体の状態に関わる機能です。
プライマリノードのダウン、セカンダリノードのダウン、レプリケーション用ネットワークのリンク中断など、さまざまな理由によりレプリケーションが一時中断した場合、同期が必要になります。DRBDの同期は、もともとの書き込み順序ではなくリニアに書き込むロジックを採用しているため、効率的です。
-
何度も書き込みが行われたブロックの場合でも、同期は1回の書き込みですみます。このため、同期は高速です。
-
ディスク上のブロックレイアウトを考慮して、わずかなシークですむよう、同期は最適化されています。
-
同期実行中は、スタンバイノードの一部のデータブロックの内容は古く、残りは最新の状態に更新されています。この状態のデータは inconsistent (不一致)と呼びます。
DRBDでは、同期はバックグラウンドで実行されるので、アクティブノードのサービスは同期によって中断されることはありません。
| データに不一致箇所が残っているノードは、多くの場合サービスに利用できません。このため、不一致である時間を可能な限り短縮することが求められます。そのため、DRBDは同期直前のLVMスナップショットを自動で作成するLVM統合機能を実装しています。これは同期中であっても対向ノードと consistent (一致する)一致するコピーを保証します。この機能の詳細についてはDRBD同期中の自動LVMスナップショットの使用を参照してください。 |
2.5.1. 可変レート同期
可変レート同期(デフォルト)の場合、DRBDは同期のネットワーク上で利用可能な帯域幅を検出し、それと、フォアグランドのアプリケーションI/Oからの入力とを比較する、完全自動制御ループに基づいて、最適な同期レートを選択します。
可変レート同期に関する設定の詳細については、可変同期速度設定を参照してください。
2.5.2. 固定レート同期
固定レート同期の場合、同期ホストに対して送信される1秒あたりのデータ量(同期速度)には設定可能な静的な上限があります。この上限に基づき、同期に必要な時間は、次の簡単な式で予測できます。
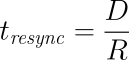
tsync は同期所要時間の予測値です。 D は同期が必要なデータ量で、リンクが途絶えていた間にアプリケーションによって更新されたデータ量です。 R は設定ファイルに指定した同期速度です。ただし実際の同期速度はネットワークやI/Oサブシステムの性能による制約を受けます。
固定レート同期に関する設定の詳細については同期速度の設定を参照してください。
2.5.3. チェックサムベース同期
DRBDの同期アルゴリズムは、データダイジェスト(チェックサム)を使うことによりさらに効率化されています。チェックサムベースの同期を行うことで、より効率的に同期対象ブロックの書き換えが行われます。DRBDは同期を行う前にブロックを読み込みディスク上のコンテンツのハッシュを計算します。このハッシュと、相手ノードの同じセクタのハッシュを比較して、値が同じであれば、そのブロックを同期での書き換え対象から外します。これにより、DRBDが切断モードから復旧し再同期するときなど、同期時間が劇的に削減されます。
同期に関する設定の詳細はチェックサムベース同期の設定を参照してください。
2.6. レプリケーションの中断
DRBDが正しく設定されていれば、DRBDはレプリケーションネットワークが輻輳していることを検出し、レプリケーションを中断します。この場合、プライマリノードはセカンダリから引き離され一時的に同期しない状態になりますが、セカンダリでは一致するコピーを保持したままです。帯域幅が確保されると、自動で同期が再開し、バックグラウンド同期が行われます。
レプリケーションの中断は、データセンタやクラウドインスタンス間との共有接続で遠隔地レプリケーションを行うような、可変帯域幅での接続の場合に通常利用されます。
輻輳のポリシーとレプリケーションの停止についてほ詳細は輻輳ポリシーと中断したレプリケーションの構成をご参照ください。
2.7. オンライン照合
オンライン照合機能を使うと、2ノードのデータの整合性を、ブロックごとに効率的な方法で確認できます。
ここで効率的というのはネットワーク帯域幅を効率的に利用することを意味しています。また、照合によって冗長性が損なわれることはありません。しかしオンライン照合はCPU使用率やシステム負荷を高めます。この意味では、オンライン照合はリソースを必要とします。
一方のノード(照合ソース)で、低レベルストレージデバイスのブロックごとのダイジェストを計算します。DRBDはダイジェストを他方のノード(照合ターゲット)に転送し、そこでローカルの対応するブロックのダイジェストと照合します。ダイジェストが一致しないブロックはout-of-syncとマークされ、後で同期が行われます。DRBDが転送するのはダイジェストであって、ブロックのデータそのものではありません。このため、オンライン照合はネットワーク帯域幅をきわめて効率的に活用します。
このプロセスは、照合対象のDRBDリソースを利用したまま実行できます。これがオンラインの由来です。照合によるパフォーマンス低下は避けられませんが、照合およびその後の同期作業全体を通じてサービスの停止やシステム全体を停止する必要はありません。
オンライン照合は、週または月に1回程度の頻度でcronデーモンから実行するのが妥当です。オンライン照合機能を有効にして実行する方法や、これを自動化する方法については、オンラインデバイス照合の使用を参照してください。
2.8. レプリケーション用トラフィックの整合性チェック
DRBDは、暗号手法にもとづくMD5、SHA-1またはCRD-32Cを使って、ノード間のメッセージの整合性をチェックできます。
DRBD自身はメッセージダイジェストアルゴリズムを備えていません。Linuxカーネルの暗号APIが提供する機能を単に利用するだけです。したがって、カーネルが備えるアルゴリズムであれば、どのようなものでも利用可能です。
本機能を有効にすると、レプリケート対象のすべてのデータブロックごとのメッセージダイジェストが計算されます。レプリケート先のDRBDは、レプリケーション用パケットの照合にこのメッセージダイジェストを活用します。データの照合が失敗したら、レプリケート先のDRBDは、失敗したブロックに関するパケットの再送を求めます。この機能を使うことで、データの損失を起こす可能性がある次のようなさまざまな状況への備えが強化され、DRBDによるレプリーションが保護されます。
-
送信側ノードのメインメモリとネットワークインタフェースの間で生じたビット単位エラー(ビット反転)。この種のエラーは、多くのシステムにおいてTCPレベルのチェックサムでは検出できません。
-
受信側ノードのネットワークインタフェースとメインメモリの間で生じたビット反転。TCPチェックサムが役に立たないのは前項と同じです。
-
何らかのリソース競合やネットワークインタフェースまたはそのドライバのバグなどによって生じたデータの損傷。
-
ノード間のネットワークコンポーネントが再編成されるときなどに生じるビット反転やデータ損傷。このエラーの可能性は、ノード間をネットワークケーブルで直結しなかった場合に考慮する必要があります。
レプリケーショントラフィックの整合性チェックを有効にする方法については、レプリケーショントラフィックの整合性チェックを設定をご参照ください。
2.9. スプリットブレインの通知と自動修復
クラスタノード間のすべての通信が一時的に中断され、クラスタ管理ソフトウェアまたは人為的な操作ミスによって両方のノードがプライマリになった場合に、スプリットブレインの状態に陥ります。それぞれのノードでデータの書き換えが行われることが可能になってしまうため、この状態はきわめて危険です。つまり、2つの分岐したデータセットが作られてしまう軽視できない状況に陥る可能性が高くなります。
クラスタのスプリットブレインは、Heartbeatなどが管理するホスト間の通信がすべて途絶えたときに生じます。これとDRBDのスプリットブレインは区別して考える必要があります。このため、本書では次のような記載方法を使うことにします。
-
スプリットブレインは、DRBDのスプリットブレインと表記します。
-
クラスタノード間のすべての通信の断絶のことをクラスタ断絶と表記します。これはクラスタのスプリットブレインのことです。
スプリットブレインに陥ったことを検出すると、DRBDは電子メールまたは他の方法によって管理者に自動的に通知できます。この機能を有効にする方法についてはスプリットブレインの通知を参照してください。
スプリットブレインへの望ましい対処方法は、手動回復を実施した後、根本原因を取り除くことです。しかし、ときにはこのプロセスを自動化する方がいい場合もあります。自動化のために、DRBDは以下のいくつかのアルゴリズムを提供します。
-
「若い」プライマリ側の変更を切り捨てる方法 ネットワークの接続が回復してスプリットブレインを検出すると、DRBDは最後にプライマリに切り替わったノードのデータを切り捨てます。
-
「若い」プライマリ側の変更を切り捨てる方法 DRBDは最初にプライマリに切り替わったノードの変更を切り捨てます。
-
変更が少ないプライマリ側の変更を切り捨てる方法 DRBDは2つのノードでどちらが変更が少ないかを調べて、少ない方のノードのすべてを切り捨てます。
-
片ノードに変更がなかった場合の正常回復 もし片ノードにスプリットブレインの間にまったく変更がなかった場合、DRBDは正常に回復し、修復したと判断します。しかし、こういった状況はほとんど考えられません。仮にリードオンリーでファイルシステムをマウントしただけでも、デバイスへの書き換えが起きるた めです。
自動修復機能をa使うべきかどうかの判断は、個々のアプリケーションに強く依存します。変更量が少ないノードのデータを切り捨てるアプローチは、ある種のWebアプリケーションの場合適しているかもしれません。一方で、金融関連のデータベースアプリケーションでは、どのような変更であっても自動的に切り捨てるようなことは受け入れがたく、どのようなスプリットブレインの場合でも手動回復が望ましいでしょう。スプリットブレイン自動修復機能を使う場合、アプリケーションの特性を十分に考慮してください。
DRBDのスプリットブレイン自動修復機能を設定する方法については、スプリットブレインからの自動復旧ポリシーを参照してください。
2.10. ディスクフラッシュのサポート
ローカルディスクやRAID論理ディスクでライトキャッシュが有効な場合、キャッシュにデータが記録された時点でデバイスへの書き込みが完了したと判断されます。このモードは一般にライトバックモードと呼ばれます。このような機能がない場合の書き込みはライトスルーモードです。ライトバックモードで運用中に電源障害が起きると、最後に書き込まれたデータはディスクにコミットされず、データを紛失する可能性があります。
この影響を緩和するために、DRBDはディスクフラッシュを活用します。ディスクフラッシュは書き込みオペレーションのひとつで、対象のデータが安定した(不揮発性の)ストレージに書き込まれるまで完了しません。すなわち、キャッシュへの書き込みではなくディスクへの書き込みを保証します。DRBDは、レプリケートするデータとそのメタデータをディスクに書き込むときに、フラッシュ命令を発行します。実際には、DRBDはアクティビティログの更新時や書き込みに依存性がある場合などにはライトキャッシュへの書き込みを迂回します。このことにより、電源障害の可能性に対する信頼性が高まっています。
しかしDRBDがディスクフラッシュを活用できるのは、直下のディスクデバイスがこの機能をサポートしている場合に限られることに注意してください。最近のカーネルは、ほとんどのSCSIおよびSATAデバイスに対するフラッシュをサポートしています。LinuxソフトウェアRAID (md)は、直下のデバイスがサポートする場合に限り、RAID-1に対してフラッシュをサポートします。デバイスマッパ(LVM2、dm-raid、マルチパス)もフラッシュをサポートしています。
電池でバックアップされた書き込みキャッシュ(BBWC)は、電池からの給電による消失しないストレージです。このようなデバイスは、電源障害から回復したときに中断していたディスクへの書き込みをディスクにフラッシュできます。このため、キャッシュへの書き込みは、事実上安定したストレージへの書き込みと同等とみなせます。この種のデバイスが使える場合、DRBDの書き込みパフォーマンス向上させるためにフラッシュを無効に設定できます。詳細は下位デバイスのフラッシュを無効にするを参照ください。
2.11. ディスクエラー処理ストラテジー
どちらかのノードのDRBD下位ブロックデバイスがI/Oエラーを返したときに、DRBDがそのエラーを上位レイヤ(多くの場合ファイルシステム)に伝えるかどうかを制御できます。
pass onを指定すると、下位レベルのエラーをDRBDはそのまま上位レイヤに伝えます。したがって、そのようなエラーへの対応(ファイルシステムをリードオンリーでマウントしなおすなど)は上位レイヤに任されます。このモードはサービスの継続性を損ねることがあるので、多くの場合推奨できない設定だといえます。
detach を設定すると、最初の下位レイヤでのI/Oエラーに対して、DRBDは自動的にそのレイヤを切り離します。上位レイヤにI/Oエラーは伝えられず、該当ブロックのデータはネットワーク越しに対向ノードに書き込まれます。その後DRBDはディスクレスモードと呼ばれる状態になり、すべてのI/Oは対向ノードに対して読み込んだり、書き込むようになります。このモードでは、パフォーマンスは犠牲になりますが、サービスは途切れることなく継続できます。また、都合のいい任意の時点でサービスを対向ノードに移動させることができます。
I/Oエラー処理方針を設定する方法についてはI/Oエラー処理方針の設定を参照してください。.
2.12. 無効データの処理ストラテジー
DRBDはデータの inconsistent(不整合状態) と outdated(無効状態) を区別します。不整合とは、いかなる方法でもアクセスできずしたがって利用できないデータ状態です。たとえば、進行中の同期先のデータが不整合データの例です。この場合、ノードのデータは部分的に古く、部分的に新しくなっており、ノード間の同期は不可能になります。下位デバイスの中にファイルシステムが入っていたら、このファイルシステムは、マウントはもちろんチェックも実行できません。
無効データは、セカンダリノード上のデータで、整合状態にあるもののプライマリ側と同期していない状態のデータをさします。一時的か永続的かを問わず、レプリケーションリンクが途切れたときに、この状態が生じます。リンクが切れている状態でのセカンダリ側の無効データは、クリーンではあるものの、対向ノードのデータ更新が反映されず古いデータ状態になっている可能性があります。サービスが無効データを使ってしまうことを防止するために、DRBDは無効データをプライマリに切り替えることを許可しません。
ネットワークの中断時にセカンダリノードのデータを無効に設定するためのインタフェースをDRBDは提供しています。このための通信には、DRBDのレプリケーションリンクとは別のネットワーク通信チャネルを使います。DRBDは無効データをアプリケーションが使ってしまうことを防止するために、このノードがプライマリになることを拒絶します。本機能の完全は実装は、DRBDレプリケーションリンクから独立した通信経路を使用するクラスタ管理フレームワーク用になされていますが、 しかしこのAPIは汎用的なので、他のクラスタ管理アプリケーションでも容易に本機能を利用できます。
レプリケーションリンクが復活すると、無効に設定されたリソースの無効フラグは自動的にクリアされます。そしてバックグラウンド同期が実行されます。
誤って無効データを使ってしまうことを防止するための設定例については、DRBD無効化デーモン(dopd)を参照してください。
2.13. 3ノードレプリケーション
| この機能はDRBDバージョン8.3.0以上で使用可能です。 |
3ノードレプリケーションとは、2ノードクラスタに3番目のノードを追加してDRBDでレプリケーションするものです。この方法は、バックアップやディザスタリカバリのために使われます。この構成においては、DRBD Proxyによる遠距離レプリケーションの内容も関係しています。
3ノードレプリケーション既存のDRBDリソースの上にもうひとつのDRBDリソースを積み重ねることによって実現されます。次の図を参照してください。
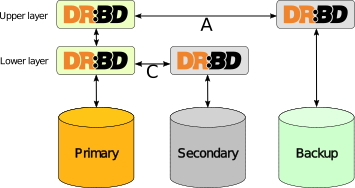
下位リソースのレプリケーションには同期モード(DRBDプロトコルC)を使いますが、上位リソースは非同期レプリケーション(DRBDプロトコルA)で動作させます。
3ノードレプリケーションは、常時実行することも、オンデマンドで実行することもできます。常時レプリケーションでは、クラスタ側のデータが更新されると、ただちに3番目のノードにもレプリケートされます。オンデマンドレプリケーションでは、クラスタシステムとバックアップサイトの通信はふだんは停止しておき、cronなどによって定期的に夜間などに同期をはかります。
2.14. DRBD Proxyによる遠距離レプリケーション
| この機能はDRBD 8.2.7以降で利用可能です。 |
DRBDのprotocol Aは非同期モードです。しかし、ソケットの出力バッファが一杯になると(
drbd.conf マニュアルページの sndbuf-size
を参照ください。)、アプリケーションからの書き込みはブロックされてしまいます。帯域幅が狭いネットワークを通じて書き込みデータが対向ノードに送られるまで、そのデータを書き込んだアプリケーションは待たなければなりません。
平均的な書き込み帯域幅は、利用可能なネットワークの帯域幅によって制約されます。ソケットの出力バッファに収まるデータ量までのバースト的な書き込みは、問題なく処理されます。
オプション製品のDRBD Proxyのバッファリング機構を使って、この制約を緩和できます。DRBDプライマリノードからの書き込みデータは、DRBD Proxyのバッファに格納されます。DRBD Proxyのバッファサイズは、アドレス可能空間や搭載メモリの範囲内で自由に設定できます。
データ圧縮を行うように設定することも可能です。圧縮と展開は、応答時間をわずかに増やしてしまいます。しかしネットワークの帯域幅が制約要因になっているのなら、転送時間の短縮効果は、圧縮と展開によるオーバヘッドを打ち消します。
圧縮展開機能は複数CPUによるSMPシステムを想定して実装され、複数CPUコアをうまく活用できます。
多くの場合、ブロックI/Oデータの圧縮率は高く、帯域幅の利用効率は向上します。このため、DRBD Proxyを使うことによって、DRBDプロトコルBまたはCを使うことも現実的なものとなります。
DRBD Proxyの設定についてはUsing DRBD Proxyを参照ください。
| DRBD ProxyはオープンソースライセンスによらないDRBDプロダクトファミリの製品になります。評価や購入については [email protected] へご連絡ください。 |
2.15. トラック輸送によるレプリケーション
トラック輸送(またはディスク輸送)によるレプリケーションは、ストレージメディアを遠隔サイトに物理的に輸送することによるレプリケーションです。以下の制約がある場合に、この方法はとくに有効です。
-
レプリケート対象データ領域がかなり大きい(数百GB以上)
-
レプリケートするデータの期待される変更レートは巨大ではない
-
利用可能なサイト間のネットワーク帯域幅が限られている
このような状況にある場合、トラック輸送を使わなければ、きわめて長期間(数日から数週間またはそれ以上)の初期同期が必要になってしまいます。トラック輸送でデータを遠隔サイトに輸送する場合、初期同期時間を劇的に短縮できます。詳細はトラックベースのレプリケーションの使用をご覧ください。
2.16. 動的対向ノード
| この記述方法はDRBDバージョン8.3.2以上で使用できます。 |
DRBDのやや特殊な使用方法となる設定値として、動的対向ノードがあります。動的対向ノードを設定すると、DRBDのペア同士は特定の名前のホストに接続せず、いくつかのホスト間を動的に選択して接続するする能力を持ちます。この設定において、DRBDは相手ノードをホスト名ではなくIPアドレスで識別します。
動的対向ノードの設定については2セットのSANベースPacemakerクラスタ間をDRBDでレプリケートを参照ください。
DRBDのコンパイル、インストールおよび設定
3. コンパイル済みDRBDバイナリパッケージのインストール
3.1. LINBIT社が提供するパッケージ
DRBDプロジェクトのスポンサー企業であるLINBIT社は、商用サポート対象のお客様向けにDRBDバイナリパッケージを提供しています。これらパッケージは http://linbit.com/support/ から入手可能であり、「公式DRBDビルド」です。
これらのビルドは次のディストリビューションで入手できます。
-
Red Hat Enterprise Linux (RHEL)バージョン5、6、7
-
SUSE Linux Enterprise Server (SLES)バージョン11SP4、12
-
Debian GNU/Linux, 8 (jessie)、9 (stretch)
-
Ubuntu Server Edition LTS 14.04 (Trusty Tahr)、16.04 (Xenial Xerus)、LTS 18.04 (Bionic Beaver)
LINBIT社では、新規のDRBDソースのリリースと並行してバイナリビルドをリリースしています。
RPMベースのシステム(SLES、RHEL)へのパッケージのインストールはパッケージ名とともに rpm -i (新規インストールの場合)または
rpm -U (アップグレードの場合)コマンドを呼び出すことで簡単に行えます。
Debianベースのシステム(Debian GNU/Linux、Ubuntu)では、 drbd8-utils と drbd8-module
パッケージを dpkg -i または gdebi コマンドでインストールします(該当する場合)。
3.2. ディストリビューションベンダが提供するパッケージ
コンパイル済みバイナリパッケージを含め、いくつかのディストリビューションでDRBDが配布されています。これらのパッケージに対するサポートは、それぞれのディストリビュータが提供します。リリースサイクルは、DRBDソースのリリースより遅れる場合があります。
3.2.1. SUSE Linux Enterprise Server
SUSE Linux Enterprise Server (SLES)バージョン9、10にはDRBD 0.7が含まれ、SLES 11 High Availability Extension (HAE) SP1 にはDRBD 8.3が含まれます。
SLESの場合、DRBDは通常はYaST2のソフトウェアインストールコンポーネントによりインストールされます。これは High Availabilityパッケージセレクションに同梱されています。
コマンドラインを使用してインストールする場合は、次のコマンドを実行します。
yast -i drbd
または
zypper install drbd
3.2.2. Debian GNU/Linux
Debian GNU/Linuxリリース5.0 ( lenny )以降にDRBD 8が含まれ、Linuxカーネル2.6.32である6.0 (
squeeze )では、Debianには移植バージョンのDRBDが提供されています。
DRBDがストックカーネルに含まれているため、 squeeze で必要なのは drbd8-utils パッケージのインストールのみです。
apt-get install drbd8-utils
lenny (obsolete)では、次のようにしてDRBDをインストールします。
apt-get install drbd8-utils drbd8-module
3.2.3. CentOS
CentOSのリリース5からDRBD 8が含まれています。
DRBDは yum コマンドでインストールできます( extras リポジトリ (または EPEL / ELRepo)
が有効になっている事が必要な事に注意してください)。
yum install drbd kmod-drbd
3.2.4. Ubuntu Linux
UbuntuにDRBDをインストールするには次のコマンドを実行します。
apt-get update apt-get install drbd8-utils
古いUbuntuのバージョンでは、 drbd8-module
も明示的にインストールする必要があります。新しいバージョンではデフォルトのカーネルにすでにアップストリームのDRBDバージョンが含まれています。
3.3. ソースからパッケージをコンパイル
github のgit
tagsで生成されたリリースは、特定の時刻のgitリポジトリのスナップショットであり、マニュアルページ、 configure
スクリプト、他の生成ファイル不足などで使用したくないかもしれません。tarballからビルドする場合は、
https://linbit.com/en/drbd-community/drbd-download/ を使用してください。
すべてのプロジェクトには、標準のビルドスクリプト( Makefile 、 configure
)が含まれています。ディストリビューションごとに特定の情報を維持することは手間がかかり、歴史的にこれらの情報はすぐに古くになっています。標準的な方法でソフトウェアをビルドする方法がわからない場合は、LINBITが提供するパッケージの使用を検討してください。
4. DRBDの設定
4.1. 下位レベルストレージの準備
DRBDをインストールしたら、両方のクラスタノードにほぼ同じ容量の記憶領域を用意する必要があります。これがDRBDリソースの下位レベルデバイスになります。システムの任意のブロックデバイスを下位レベルデバイスとして使用できます。たとえば、次のようなものがあります。
-
ハードドライブのパーティション(または物理ハードドライブ全体)
-
ソフトウェアRAIDデバイス
-
LVM論理ボリュームまたはLinuxデバイスマッパインフラストラクチャによって構成されるその他のブロックデバイス
-
システム内のその他のブロックデバイス。
リソースを積み重ねることもできます。つまり、DRBDデバイスを他のDRBDデバイスの下位レベルのデバイスとして利用することができます。リソースの積み重ねにはいくつかの注意点があります。詳しくは3ノード構成の作成を参照ください。
| ループデバイスをDRBDの下位レベルデバイスとして使用することもできますが、デッドロックの問題があるためお勧めできません。 |
DRBDリソースを作成する前に、そのストレージ領域を空にしておく必要はありません。DRBDを使用して、非冗長のシングルサーバシステムから、2ノードのクラスタシステムを作成することは一般的なユースケースですが、いくつか重要な注意点があります。(その場合には)DRBDメタデータを参照ください)
本ガイドの説明は、次のようなとてもシンプルな構成を前提としています。
-
両ホストには使用可能な(現在未使用の)
/dev/sda7というパーティションがある。 -
内部メタデータを使用する。
4.2. ネットワーク構成の準備
必須要件ではありませんが、DRBDによるレプリケーションの実行には、専用接続を使用することをお勧めします。この書き込みには、ギガビットイーサネットどうしをケーブルで直結した接続が最適です。DRBDをスイッチを介して使用する場合には、冗長コンポーネントと
bonding ドライバ( active-backup モードで)の使用を推奨します。
一般に、ルータを介してDRBDレプリケーションを行うことはお勧めできません。スループットと待ち時間の両方に悪影響を及ぼし、パフォーマンスが大幅に低下します。
ローカルファイアウォールの要件として重要な点は、通常、DRBDは7788以上のTCPポートを使用し、それぞれのTCPリソースが個別のTCPポート上で待機するということです。設定したリソースすべてで、DRBDは2つのTCP接続を使用します。これらの接続が許可されるようにファイアウォールを設定する必要があります。
SELinuxやAppArmorなどのMAC (Mandatory Access Control)スキーマが有効な場合は、ファイアウォール以外のセキュリティ要件も適用される場合があります。DRBDが正しく機能するように、 必要に応じてローカルセキュリティポリシーを調整してください。
また、DRBDに使用するTCPポートを別のアプリケーションが使用していないことも確認してください。
複数のTCPポートをサポートするようにDRBDリソースを設定することはできません。DRBD接続に負荷分散や冗長性が必要な場合は、イーサネットレベルで簡単に実現できます(この場合もボンディングドライバを使用してください)。
本ガイドの説明は、次のようなとてもシンプルな構成を前提としています。
-
2つのDRBDホストそれぞれに、現在使用されていないネットワークインタフェース
eth1が存在する(IPアドレスはそれぞれ10.1.1.31と10.1.1.32) -
どちらのホストでも他のサービスがTCPポート7788〜7799を使用していない。
-
ローカルファイアウォール設定は、これらのポートを介したホスト間のインバウンドとアウトバウンドの両方のTCP接続を許可する。
4.3. リソースの設定
DRBDのすべての機能は、設定ファイル /etc/drbd.conf で制御されます。通常、この設定ファイルは、次のような内容となっています。
include "/etc/drbd.d/global_common.conf"; include "/etc/drbd.d/*.res";
通例、 /etc/drbd.d/global_common.conf
にはDRBD設定の、globalとcommonのセクションが含まれます。また、
.res ファイルには各リソースセクションが含まれます。
drbd.conf に include
ステートメントを使用せずにすべての設定を記載することも可能です。しかし、設定の見やすさの観点からは、複数のファイルに分割することをお勧めします。
いずれにしても drbd.conf や、その他の設定ファイルは、すべてのクラスタノードで正確に同じである必要があります。
DRBDのソースtarファイルの scripts
サブディレクトリに、サンプル設定ファイルがあります。バイナリインストールパッケージの場合、サンプル設定ファイルは直接 /etc
にインストールされるか、 /usr/share/doc/packages/drbd などのパッケージ固有の文書ディレクトリにインストールされます。
このセクションは、DRBDの使用を開始するため、必ず理解しておく必要のある設定ファイルの項目についての説明です。設定ファイルの構文と内容の詳細については、
drbd.conf のマニュアルページを参照してください。
4.3.1. 設定例
本ガイドでの説明は、前章で挙げた例をもとした最小限の構成を前提としています。
/etc/drbd.d/global_common.conf )global {
usage-count yes;
}
common {
net {
protocol C;
}
}
/etc/drbd.d/r0.res )resource r0 {
on alice {
device /dev/drbd1;
disk /dev/sda7;
address 10.1.1.31:7789;
meta-disk internal;
}
on bob {
device /dev/drbd1;
disk /dev/sda7;
address 10.1.1.32:7789;
meta-disk internal;
}
}
この例では、DRBDが次のように構成されます。
-
DRBDの使用状況の統計をオプトインとして含める(
usage-countを参照). -
完全に同期したレプリケーションを使用するようにリソースを設定する(Protocol C)
-
クラスタには2つのノード ‘alice’ と ‘bob’ がある。
-
任意の名前
r0を持つリソースがあり/dev/sda7下位レベルデバイスとして使用する。このリソースは、内部メタデータによって設定されている。 -
リソースはネットワーク接続にTCPポート7789を使用し、それぞれIPアドレス10.1.1.31と10.1.1.32にバインドされる。
暗黙的に、上記の設定はリソースの1つのボリュームを作成し、ゼロ( 0
)番号が付与されます。1つのリソースに複数のボリュームを設定する場合には、次のようにします。
/etc/drbd.d/r0.res )resource r0 {
volume 0 {
device /dev/drbd1;
disk /dev/sda7;
meta-disk internal;
}
volume 1 {
device /dev/drbd2;
disk /dev/sda8;
meta-disk internal;
}
on alice {
address 10.1.1.31:7789;
}
on bob {
address 10.1.1.32:7789;
}
}
| ボリュームは既存のデバイスの動作中にも追加できます。新しいDRBDボリュームを既存のボリュームグループへ追加するを参照ください。 |
4.3.2. global セクション
このセクションは設定の中で1回しか使用できません。通常この設定は /etc/drbd.d/global_common.conf
ファイルに記述します。設定ファイルが1つの場合は、設定ファイルの一番上に記述します。このセクションで使用できるオプションはわずかですが、ほとんどのユーザの場合、必要なのは次の1つだけです。
usage-countDRBDプロジェクトはさまざまなバージョンのDRBDの使用状況について統計を取ります。これは、システムに新規のDRBDバージョンがインストールされるたびに、HTTPサーバに接続することにより実行されます。これを無効にするには、
usage-count no; と指定します。デフォルトは usage-count ask;
で、DRBDをアップグレードするたびにプロンプトが表示されます。
DRBDの使用状況の統計は公開されています。http://usage.drbd.org[http://usage.drbd.org]をご参照ください。
4.3.3. common セクション
このセクションで、各リソースに継承される設定を簡単に定義できます。通常この設定は /etc/drbd.d/global_common.conf
に記述します。ここで定義するオプションは、リソースごとに定義することもできます。
common
セクションは必須ではありませんが、複数のリソースを使用する場合は、記述することを強くお勧めします。これにより、オプションを繰り返し使用することによって設定が複雑になることを回避できます。
上記の例では、 net{ protocol C;} が common セクションで指定されているため、設定されているすべてのリソース( r0
含む)がこのオプションを継承します。ただし、明示的に別の protocol
オプションが指定されている場合は除きます。使用可能なその他の同期プロトコルについては、レプリケーションのモードを参照してください。
4.3.4. resource セクション
各リソースの設定ファイルは、通常 /etc/drbd.d/<resource>.res
という名前にします。定義するDRBDリソースは、設定ファイルでresource
nameを指定して名前を付ける必要があります。任意の名前を使用できますが、空白を除くUS-ASCII文字セットを使う必要があります。
各リソースには2つの on <host> サブセクションも必要です(各クラスタノードに1つずつ)。その他すべての設定は common
セクション(記述した場合)から継承されるか、DRBDのデフォルト設定から取得されます。
さらに、オプションの値が両方のホストで等しい場合は、直接 resource
セクションで指定することができます。このため、設定例は次のように短くすることができます。
resource r0 {
device /dev/drbd1;
disk /dev/sda7;
meta-disk internal;
on alice {
address 10.1.1.31:7789;
}
on bob {
address 10.1.1.32:7789;
}
}
4.4. リソースを初めて有効にする
すでに述べた手順に従って最初のリソース設定を完了したら、リソースを稼働させます。
両方のノードに対して、次の手順を行います。
さきほどの構成例( resource r0{ … } )では、 <resource> は r0 となります。
この手順は、最初にデバイスを作成するときにのみ必要です。これにより、DRBDのメタデータを初期化します。
# drbdadm create-md <resource> v08 Magic number not found Writing meta data... initialising activity log NOT initializing bitmap New drbd meta data block sucessfully created.
これにより、リソースとそのバッキングデバイス(マルチボリュームリソースの場合は、すべてのデバイス)とを結びつけます。また、対向ノードのリソースと接続します。
# drbdadm up <resource>
/proc/drbd/proc ファイルシステムにあるDRBDの仮想状態ファイル /proc/drbd ,に次のような情報が記述されています。
# cat /proc/drbd
version: 8.4.1 (api:1/proto:86-100)
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by buildsystem@linbit, 2011-12-20 12:58:48
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:524236
| この時点では Inconsistent/Inconsistent のディスク状態になっているはずです。 |
これで、DRBDがディスクリソースとネットワークリソースに正しく割り当てられ、稼働できるようになりました。次に、どちらのノードをデバイスの初期同期のソースとして使用するか指定する必要があります。
4.5. デバイスの初期同期
DRBDを完全に機能させるには、さらに次の2つの手順が必要です。
新しく初期化した空のディスクを使用する場合は、任意のディスクを同期元にできます。いずれかのノードにすでに重要なデータが格納されている場合は、十分注意して必ずそのノードを同期元として選択してください。デバイスの初期同期の方向が誤っていると、データを失うおそれがあります。慎重に行ってください。
この手順は、最初のリソース設定の際に、同期ソースとして選択した1つのノードに対してのみ実行します。次のコマンドで実行します。
# drbdadm primary --force <resource>
このコマンドを指定すると、初期フル同期が開始します。 /proc/drbd
で同期の進行状況を監視できます。デバイスのサイズによっては、同期に時間がかかる場合があります。
この時点で、初期同期が完了していなくてもDRBDデバイスは完全に稼働します。(ただし、パフォーマンスはいくらか低いです。)次に、デバイスのファイルシステムを作成します。これを下位ブロックデバイスとして使用し、マウントして、アクセス可能なブロックデバイスでさまざまな操作を実行することができます。
リソースに対して一般的な管理タスクを行う場合は、一般的な管理作業に進んでください。
4.6. トラックベースのレプリケーションの使用
リモートノードに同期するデータを前もってロードし、デバイスの初期同期をスキップする場合は、次の手順を行います。
これは、ローカルノードに設定済みだが接続されていないプライマリロールのDRBDリソースがあることを前提とします。つまり、デバイスの設定が完了し、両方のノードに同一の
drbd.conf
のコピーが存在し最初のリソース昇格をローカルノードで実行するコマンドを発行したが、 — リモートノードがまだ接続されていない状態です。
-
ローカルノードで次のコマンドを実行します。
# drbdadm new-current-uuid --clear-bitmap <resource>
-
リソースのデータおよびそのメタデータの正確に同一のコピーを作成します。たとえば、ホットスワップ可能なRAID-1ドライブの一方を抜き取ります。この場合は、もちろん新しいドライブをセットしてRAIDセットを再構築しておくべきでしょう。抜き取ったドライブは、正確なコピーとしてリモートサイトに移動できます。別の方法としては、ローカルのブロックデバイスがスナップショットコピーをサポートする場合(LVMの上位でDRBDを使用する場合など)は、
ddを使用してスナップショットのビット単位のコピーを作ってもかまいません。 -
ローカルノードで次のコマンドを実行します。
# drbdadm new-current-uuid <resource>
この2回目のコマンドには --clear-bitmap がありません。
-
対向ホストの設置場所にコピーを物理的に移動します。
-
コピーをリモートノードに追加します。ここでも物理ディスクを接続するか、リモートノードの既存のストレージに移動したデータのビット単位のコピーを追加します。レプリケートしたデータだけでなく、関連するDRBDメタデータも必ず復元するかコピーしてください。そうでない場合、ディスクの移動を正しく行うことができません。
-
リモートノードで次のコマンドを実行します。
# drbdadm up <resource>
2つのホストを接続しても、デバイスのフル同期は開始されません。代わりに、 drbdadm --clear-bitmap
new-current-uuid の呼び出し以降に変更されたブロックのみを対象とする自動同期が開始します。
以降、データの変更が全くない場合でも、アクティビティログの領域が含まれるため、それの同期が短時間行われます。これはチェックサムベースの同期を使用することで緩和されます。
この手順は、リソースが通常のDRBDリソースの場合でもスタックリソースの場合でも使用できます。スタックリソースの場合は、 -S または
--stacked オプションを drbdadm に追加します。
DRBDの使い方
5. 一般的な管理作業
この章では、日常的な運用において必要な一般的な管理作業について説明します。トラブルシューティング作業については取り上げません。これについては、トラブルシューティングとエラーからの回復を参照してください。
5.1. DRBDの状態のチェック
5.1.1. drbd-overview で状態を取得する
DRBDのステータスは drbd-overview ユーティリティで簡単に確認できます。
# drbd-overview 0:home Connected Primary/Secondary UpToDate/UpToDate C r--- /home xfs 200G 158G 43G 79% 1:data Connected Primary/Secondary UpToDate/UpToDate C r--- /mnt/ha1 ext3 9.9G 618M 8.8G 7% 2:nfs-root Connected Primary/Secondary UpToDate/UpToDate C r--- /mnt/netboot ext3 79G 57G 19G 76%
5.1.2. drbdadm によるステータス情報
一番シンプルなものとして、1つのリソースのステータスを表示します。
# drbdadm status home
home role:Secondary
disk:UpToDate
peer role:Secondary
replication:Established peer-disk:UpToDate
ここでは、リソース home がローカル、対抗ノードにあり、UpToDate, Secondary
状態であることを示します。よって、2つのノードはストレージデバイス上で同じデータを持ち、どちらもそのデバイスを使用していません。
より多くの情報を得るには drbdsetup に --verbose , --statistics
引数のどちらか、あるいは両方を指定します:
# drbdsetup status home --verbose --statistics
home role:Secondary suspended:no
write-ordering:flush
volume:0 minor:0 disk:UpToDate
size:5033792 read:0 written:0 al-writes:0 bm-writes:0 upper-pending:0
lower-pending:0 al-suspended:no blocked:no
peer connection:Connected role:Secondary congested:no
volume:0 replication:Established peer-disk:UpToDate
resync-suspended:no
received:0 sent:0 out-of-sync:0 pending:0 unacked:0
この例では、ローカルノードについては多少異なりますが、このリソースで使用しているノードすべてを数行ごとにブロックで表示しています。以下で詳細を説明します。
各ブロックの最初の行はロール (リソースのロール を参照) を表示します。
次に重要な行は volume で始まる行で通常0から番号付けされますが、構成により他の番号付けも可能です。この行は、 replication
項に 接続状態と disk 項 (ディスク状態 を参照)
にリモートの ディスク状態を表示します。さらに received, sent,
out-of-sync などの統計情報が続きます。詳細は パフォーマンス指標 を参照してください。
ローカルノードの場合、この例では、最初の行にリソース名 home が表示されます。最初のブロックは常にローカルノードを記述するので、
Connection やアドレス情報はありません。
詳細は drbd.conf マニュアルページを参照してください。
この例の他の6行は、構成されている各DRBDデバイスについて繰り返されるブロックで、先頭にデバイスのマイナー番号が付いています。この場合、 0
はデバイス /dev/drbd0 に対応します。
リソース固有の出力には、リソースについてのさまざまな情報が表示されます。
Replication protocolはリソースが使用します。 A 、 B 、 C
のいずれかです。詳細はレプリケーションのモードを参照ください。
5.1.3. drbdsetup events2 によるワンショットもしくはリアルタイムの監視
| これは drbd-utils バージョン 8.9.3, kernel module 8.4.6 以降で利用可能です。 |
これは、監視のような自動ツールでの使用に適したもので、DRBD から情報を取得する低レベルのメカニズムです。
最も単純な呼び出しでは、現在のステータスのみを表示し、出力は次のようになります(ただし、端末で実行するとカラー属性を含みます)。
# drbdsetup events2 --now r0 exists resource name:r0 role:Secondary suspended:no exists connection name:r0 peer-node-id:1 conn-name:remote-host connection:Connected role:Secondary exists device name:r0 volume:0 minor:7 disk:UpToDate exists device name:r0 volume:1 minor:8 disk:UpToDate exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:0 replication:Established peer-disk:UpToDate resync-suspended:no exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:1 replication:Established peer-disk:UpToDate resync-suspended:no exists -
–now 引数なしではプロセスは実行し続け、このように連続的に更新し続けます:
# drbdsetup events2 r0 ... change connection name:r0 peer-node-id:1 conn-name:remote-host connection:StandAlone change connection name:r0 peer-node-id:1 conn-name:remote-host connection:Unconnected change connection name:r0 peer-node-id:1 conn-name:remote-host connection:Connecting
監視目的のために ”–statistics” 引数を指定すると、パフォーマンスカウンタや他の事象を生成できます。
# drbdsetup events2 --statistics --now r0 exists resource name:r0 role:Secondary suspended:no write-ordering:drain exists connection name:r0 peer-node-id:1 conn-name:remote-host connection:Connected role:Secondary congested:no exists device name:r0 volume:0 minor:7 disk:UpToDate size:6291228 read:6397188 written:131844 al-writes:34 bm-writes:0 upper-pending:0 lower-pending:0 al-suspended:no blocked:no exists device name:r0 volume:1 minor:8 disk:UpToDate size:104854364 read:5910680 written:6634548 al-writes:417 bm-writes:0 upper-pending:0 lower-pending:0 al-suspended:no blocked:no exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:0 replication:Established peer-disk:UpToDate resync-suspended:no received:0 sent:131844 out-of-sync:0 pending:0 unacked:0 exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:1 replication:Established peer-disk:UpToDate resync-suspended:no received:0 sent:6634548 out-of-sync:0 pending:0 unacked:0 exists -
--timestamp 引数もあります。
5.1.4. /proc/drbd でのステータス情報
”/proc/drbd” は非推奨です。8.4 シリーズでは削除されませんが、drbdadm によるステータス情報 や監視目的の
drbdsetup events2 によるワンショットもしくはリアルタイムの監視 などの他の手段に切り替えることをお勧めします。
|
/proc/drbd
は現在設定されているすべてのDRBDリソースに関するリアルタイムのステータス情報を表示する仮想ファイルです。次のようにして、ファイルの内容を確認できます。
$ cat /proc/drbd version: 8.4.0 (api:1/proto:86-100) GIT-hash: 09b6d528b3b3de50462cd7831c0a3791abc665c3 build by [email protected], 2011-10-12 09:07:35 0: cs:Connected ro:Secondary/Secondary ds:UpToDate/UpToDate C r----- ns:0 nr:0 dw:0 dr:656 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0 1: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r--- ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0 2: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r--- ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
先頭に version: と記述された最初の行は、システムで使用されているDRBDのバージョンを示します。2行目にはこのビルドに関する情報が記述されています。
この例の他の6行は、構成されている各DRBDデバイスについて繰り返されるブロックで、先頭にデバイスのマイナー番号が付いています。この場合、 0
はデバイス /dev/drbd0 に対応します。
/proc/drbd のデバイス固有の出力には、リソースについてのさまざまな情報が表示されます。
cs (connection state)ネットワーク接続の状態。接続状態の種類や詳細については接続状態を参照ください。
ro (roles)ノードのロール最初にローカルノードのロールが表示され、スラッシュの後に対向ノードのロールが表示されます。リソースロールの詳細は、リソースのロールを参照してください。
ds (disk states)ハードディスクの状態スラッシュの前にローカルノードの状態、スラッシュの後に対向ノードのハードディスクの状態が表示されます。さまざまなディスク状態についてはディスク状態をご参照ください。
Replication protocolはリソースが使用します。 A 、 B 、 C
のいずれかです。詳細はレプリケーションのモードを参照ください。
リソースのI/O状態を反映する6種のフラグです。これらフラグの詳細はI/O状態フラグを参照ください。
リソースの利用とパフォーマンスを反映したカウンタです。詳細はパフォーマンス指標を参照ください。
5.1.5. 接続状態
リソースの接続状態を確認するには、 /proc/drbd を監視するか、 drbdadm
cstate コマンドを実行します。
# drbdadm cstate <resource> Connected
リソースの接続状態には次のようなものがあります。
ネットワーク構成は使用できません。リソースがまだ接続されていない、管理上の理由で切断されている(`drbdadm disconnect`を使用)、認証の失敗またはスプリットブレインにより接続が解除された、のいずれかが考えられます。
切断中の一時的な状態です。次の状態は StandAlone です。
接続を試行する前の一時的な状態です。次に考えられる状態は、 WFConnection および WFReportParams です。
対向ノードとの通信のタイムアウト後の一時的な状態です。次の状態は Unconnected です。
対向ノードとの接続が失われた後の一時的な状態です。次の状態は Unconnected です。
対向ノードとの接続が失われた後の一時的な状態です。次の状態は Unconnected です。
対向ノードとの接続が失われた後の一時的な状態です。次の状態は Unconnected です。
一時的な状態です。対向ノードが接続を閉じています。次の状態は Unconnected です。
対向ノードノードがネットワーク上で可視になるまでノードが待機します。
TCP (伝送制御プロトコル)接続が確立され、ノードが対向ノードからの最初のネットワークパケットを待っています。
DRBDの接続が確立され、データミラー化がアクティブになっています。これが正常な状態です。
管理者により開始されたフル同期が始まっています。次に考えられる状態は SyncSource または PausedSyncS です。
管理者により開始されたフル同期が始まっています。次の状態は WFSyncUUID です。
部分同期が始まっています。次に考えられる状態は SyncSource または PausedSyncS です。
部分同期が始まっています。次に考えられる状態は WFSyncUUID です。
同期が開始されるところです。次に考えられる状態は SyncTarget または PausedSyncT です。
現在、ローカルノードを同期元にして同期を実行中です。
現在、ローカルノードを同期先にして同期を実行中です。
ローカルノードが進行中の同期の同期元ですが、現在は同期が一時停止しています。原因として、別の同期プロセスの完了との依存関係、または
drbdadm pause-sync を使用して手動で同期が中断されたことが考えられます。
ローカルノードが進行中の同期の同期先ですが、現在は同期が一時停止しています。原因として、別の同期プロセスの完了との依存関係、または
drbdadm pause-sync を使用して手動で同期が中断されたことが考えられます。
現在、ローカルノードを照合元にして、オンラインデバイスの照合を実行中です。
現在、ローカルノードを照合先にして、オンラインデバイスの照合を実行中です。
5.1.6. リソースのロール
リソースのロールは、 /proc/drbd を監視するか、
drbdadm role コマンドを発行することのいずれかによって確認できます。
# drbdadm role <resource> Primary/Secondary
左側はローカルリソースのロール、右側はリモートリソースのロールです。
リソースロールには次のようなものがあります。
現在、リソースはプライマリロールで読み書き加能です。2つのノードの一方だけがこのロールになることができます。ただし、デュアルプライマリモードが有効な場合は例外です。
現在、リソースがセカンダリロールです。対向ノードから正常に更新を受け取ることができますが(切断モード以外の場合)、このリソースに対して読み書きは実行できません。1つまたは両ノードがこのロールになることができます。
現在、リソースのロールが不明です。ローカルリソースロールがこの状態になることはありません。これは、切断モードの場合にのみ、対向ノードのリソースロールだけに表示されます。
5.1.7. ディスク状態
リソースのディスクの状態は、 /proc/drbd を監視することにより、または drbdadm dstate
コマンドを発行することのいずれかによって確認できます。
# drbdadm dstate <resource> UpToDate/UpToDate
左側はローカルディスクの状態、右側はリモートディスクの状態です。
ローカルディスクとリモートディスクの状態には、次のようなものがあります。
DRBDドライバにローカルブロックデバイスが割り当てられていません。原因として、リソースが下位デバイスに接続されなかった、
drbdadm detach を使用して手動でリソースを切り離した、または下位レベルのI/Oエラーにより自動的に切り離されたことが考えられます。
メタデータ読み取り中の一時的な状態です。
ローカルブロックデバイスがI/O障害を報告した後の一時的な状態です。次の状態は Diskless です。
すでに接続しているDRBDデバイスで接続が実行された場合の一時的状態です。
データが一致しません。新規リソースを作成した直後に(初期フル同期の前に)両方のノードがこの状態になります。また、同期中には片方のノード(同期先)がこの状態になります。
リソースデータは一致していますが、無効です。
ネットワーク接続を使用できない場合に、対向ノードディスクにこの状態が使用されます。
接続していない状態でノードのデータが一致しています。接続が確立すると、データが UpToDate か Outdated か判断されます。
データが一致していて最新の状態です。これが正常な状態です。
5.1.8. I/O状態フラグ
/proc/drbd
フィールドのI/O状態フラグは現在のリソースへのI/Oオペレーションの状態に関する情報を含みます。全部で6つのフラグがあり、次の値をとります。
-
I/O停止。I/Oの動作中には
rであり、停止中にはsです。通常時はrです。 -
シリアル再同期。リソースの再同期を待ち受け中で、 再同期後の依存性があるため延期されている場合、このフラグが
aになります。通常は-です。 -
対向ノードで開始された同期の停止。リソースの再同期を待ち受け中で、対向ノードが何らかの理由で同期を停止した場合に、このフラグが
pになります。通常は-です。 -
ローカルで開始された同期の停止。リソースの再同期を待ち受け中で、ローカルノードのユーザが同期を停止した場合、このノードが
uになります。通常は-です。 -
ローカルでブロックされたI/O。通常は
-です。次のいずれかのフラグになります。-
d: 何らかの理由でDRBD内部でI/Oがブロックされたなどの一時的な状況 -
b: 下位デバイスのI/Oがブロックされている。 -
n: ネットワークソケットの輻輳。 -
a: デバイスI/Oのブロックとネットワーク輻輳が同時に発生。
-
-
アクティビティログのアップデートの停止アクティビティログへのアップデートが停止された場合、このフラグが
sになります。通常は-です。
5.1.9. パフォーマンス指標
/proc/drbd の2行目の各リソースの情報は次のカウンタを含んでいます。
ns (ネットワーク送信)ネットワーク接続を介して対向ノードに送信された正味データの量(単位はKibyte)。
nr (ネットワーク受信)ネットワーク接続を介して対向ノードが受信した正味データの量(単位はKibyte)。
dw (ディスク書き込み)ローカルハードディスクに書き込まれた正味データ(単位はKibyte)。
dr (ディスク読み取り)ローカルハードディスクから読み取った正味データ(単位はKibyte)。
al (アクティビティログ)メタデータのアクティビティログ領域の更新の数。
bm (ビットマップ)メタデータのビットマップ領域の更新の数。
lo (ローカルカウント)DRBDが発行したローカルI/Oサブシステムに対するオープン要求の数。
pe (保留)対向ノードに送信されたが、対向ノードから応答がない要求の数。
ua (未確認)ネットワーク接続を介して対向ノードが受信したが、応答がない要求の数。
ap (アプリケーション保留)DRBDに転送されたが、DRBDが応答していないブロックI/O要求の数。
ep (エポック)エポックオブジェクトの数。通常は1。 barrier または none
書き込み順序付けメソッドを使用する場合は、I/O負荷により増加する可能性があります。
wo (書き込み順序付け)現在使用されている書き込み順序付けメソッド。 b (バリア)、 f (フラッシュ)、 d (ドレイン)または n (なし)。
oos (非同期)現在、同期していないストレージの量(単位はKibibyte)。
5.2. リソースの有効化と無効化
5.2.1. リソースの有効化
クラスタ構成に応じたクラスタ管理アプリケーションの操作によって、通常、すべての構成されているDRBDリソースが自動的に有効になります。
-
by a cluster resource management application at its discretion, based on your cluster configuration, or
-
またはシステム起動時の
/etc/init.d/drbdによっても有効になります。
もし何らかの理由により手動でリソースを起動する必要のある場合、以下のコマンドの実行によって行うことができます。
# drbdadm up <resource>
他の場合と同様に、特定のリソース名の代わりにキーワード all を使用すれば、 /etc/drbd.conf
で構成されているすべてのリソースを一度に有効にできます。
5.2.2. リソースを無効にする
特定のリソースを一時的に無効にするには、次のコマンドを実行します。
# drbdadm down <resource>
ここでも、リソース名の代わりにキーワード all を使用して、1回で /etc/drbd.conf
に記述されたすべてのリソースを一時的に無効にできます。
5.3. リソースの設定の動的な変更
動作中のリソースのパラメータを変更できます。次の手順を行います。
-
/etc/drbd.confのリソース構成を変更します。 -
両方のノードで
/etc/drbd.confファイルを同期します。 -
両ノードで
drbdadm adjust <resource>コマンドを実行します。
drbdadm adjust は drbdsetup を通じて実行中のリソースを調整します。保留中の drbdsetup
呼び出しを確認するには、 drbdadm を -d (予行演習)オプションをつけて実行します。
/etc/drbd.conf の common セクションを変更して一度にすべてのリソースに反映させたいときは、 drbdadm adjust
all を実行します。
|
5.4. リソースの昇格と降格
手動でリソースロールをセカンダリからプライマリに切り替える(昇格)、またはその逆に切り替える(降格)には、次のコマンドを実行します。
# drbdadm primary <resource> # drbdadm secondary <resource>
DRBDがシングルプライマリモード
(DRBDのデフォルト)で、接続状態が Connected
の場合、任意のタイミングでどちらか1つのノード上でのみリソースはプライマリロールになれます。したがって、 <resource>
が対向ノードがプライマリロールになっているときに drbdadm primary <resource> を実行すると、エラーが発生します。
リソースがデュアルプライマリモードに対応するように設定されている場合は、両方のノードをプライマリロールに切り替えることができます。
5.5. 基本的な手動フェイルオーバ
Pacemakerを使わず、パッシブ/アクティブ構成でフェイルオーバを手動で制御するには次のようにします。
現在のプライマリノードでDRBDデバイスを使用するすべてのアプリケーションとサービスを停止し、リソースをセカンダリに降格します。
# umount /dev/drbd/by-res/<resource> # drbdadm secondary <resource>
プライマリにしたいノードでリソースを昇格してデバイスをマウントします。
# drbdadm primary <resource> # mount /dev/drbd/by-res/<resource> <mountpoint>
5.6. DRBDをアップグレードする
DRBDのアップグレードは非常にシンプルな手順です。このセクションでは8.3.xから8.4.xへのアップグレードを扱いますが、この手順は他のアップグレードでも使えます。
5.6.1. リポジトリをアップデートする
8.3から8.4の間で多くの変更があったため、それぞれ別個のリポジトリを作りました。両ノードでリポジトリのアップデートを行います。
RHEL/CentOSシステム
/etc/yum.repos.d/linbit.repos.d/linbit.repoファイルに次の変更を反映するよう編集します。
[drbd-8.4] name=DRBD 8.4 baseurl=http://packages.linbit.com/<hash>/8.4/rhel6/<arch> gpgcheck=0
| <hash>と<arch>の部分を埋める必要があります。<hash>キーは、LINNBITサポートから入手します。 |
Debian/Ubuntuシステム
次の変更点を/etc/apt/sources.listへ反映させるため編集します。
deb http://packages.linbit.com/<hash>/8.4/debian squeeze main
| <hash> の部分を埋める必要があります。<hash>キーは、LINNBITサポートから入手します。 |
次にDRBDの署名キーを信頼済みキーに追加します。
# gpg --keyserver subkeys.pgp.net --recv-keys 0x282B6E23 # gpg --export -a 282B6E23 | apt-key add -
最後にDebianに認識させるためapt-get updateを実行します。
apt-get update
5.6.2. パッケージをアップグレードする
最初に、リソースが同期している事を確認してください。’cat /proc/drbd’がUpToDate/UpToDateを出力しています。
bob# cat /proc/drbd
version: 8.3.12 (api:88/proto:86-96)
GIT-hash: e2a8ef4656be026bbae540305fcb998a5991090f build by buildsystem@linbit, 2011-10-28 10:20:38
0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:33300 dw:33300 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
リソースが同期している事が確認できたので、セカンダリノードのアップグレードから始めます。これは手動で実行できますが、Pacemakerを使用している場合にはスタンバイモードにしてください。どちらの方法についても、以下をご覧ください。Pacemakerを動作させている場合には、手動の方法は実施しないでください。
-
手動の方法
bob# /etc/init.d/drbd stop
-
Pacemaker
セカンダリノードをスタンバイモードにします。この例は bob がセカンダリの場合です。
bob# crm node standby bob
| “Unconfigured”と表示されるまでは、クラスタの状態を’crm_mon -rf’または’cat /proc/drbd’で確認できます。 |
yumまたはaptでパッケージをアップデートします。
bob# yum upgrade
bob# apt-get upgrade
セカンダリノードのボブでアップグレードが終わり、最新のDRBD 8.4カーネルモジュールとdrbd-utilsになったらDRBDを開始します。
-
手動
bob# /etc/init.d/drbd start
-
Pacemaker
# crm node online bob
bobの’cat /proc/drbd’の出力結果が8.4.xを示し、次のようになっています。
version: 8.4.1 (api:1/proto:86-100)
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by buildsystem@linbit, 2011-12-20 12:58:48
0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:12 dw:12 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
| プライマリノードのaliceでは、アップグレードをするまで’cat /proc/drbd’が以前のバージョンを示しています。 |
この時点では異なるバージョンのDRBDが混在しています。プライマリノードのaliceでDRBDを使用するすべてのサービスを停止したら、bobを昇格します。繰り返しですが、この操作は手動でもPacemakerのシェルからでも行えます。
-
手動
alice # umount /dev/drbd/by-res/r0 alice # /etc/init.d/drbd stop bob # drbdadm primary r0 bob # mount /dev/drbd/by-res/r0/0 /mnt/drbd
マウントコマンドは現在、リソースのボリュームナンバーを定義している’/0’を参照している点に注意してください。新しいボリュームの特徴の詳細についてはボリュームを参照してください。
-
Pacemaker
# crm node standby alice
| この手順は動作中のサービスを停止させてセカンダリサーバのbobへ移行させます。 |
この状態でDRBDをyumまたはaptを使って安全にアップグレードできます。
alice# yum upgrade
alice# apt-get upgrade
アップグレードが完了したらaliceサーバは最新バージョンのDRBDとなり、起動できるようになります。
-
手動
alice# /etc/init.d/drbd start
-
Pacemaker
alice# crm node online alice
| サービスはbobサーバに残ったままであり、手動で戻さない限りそのままです。 |
これで両サーバのDRBDはconnectedの状態で最新バージョンとなります。
version: 8.4.1 (api:1/proto:86-100)
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by buildsystem@linbit, 2011-12-20 12:58:48
0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:12 dw:12 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
5.6.3. 構成の移行
DRBD 8.4は8.3の構成と後方互換性がありますが、いくつかの構文は変更になっています。すべての変更点の一覧は構成における構文の変更点を参照してください。’drbdadm dump all’コマンドを使うことで、古い構成をとても簡単に移すことができます。新しいリソース構成ファイルに続いて新しいグローバル構成も両方とも出力します。この出力を使って変更を適宜行ってください。
5.7. DRBD 8.4を8.3にダウングレードする。
DRBD 8.4を使っていて8.3に戻したい場合、従わなければいけないいくつかの手順があります。このセクションでは、現在8.4のカーネルモジュールをつかっており、8.4のユーティリティがインストールされていると仮定します。
DRBDリソースにアクセスしているサービスを停止し、アンマウントし、デバイスをセカンダリに降格します。それから次のコマンドを実行します。
| これらの手順は両サーバで完了する必要があります。 |
drbdadm down all drbdadm apply-al all rmmod drbd
LINBITリポジトリを使用している場合には apt-get remove drbd8-utils drbd8-module-`uname -r
または yum remove drbd kmod-drbd でパッケージを削除できます。
8.4が削除されたので8.3をインストールします。インストールはリポジトリを8.3に戻すことでも、http://www.drbd.jp/users-guide/p-build-install-configure.html[8.3ユーザーズガイド]の手順でも行えます。
| 構成を8.4フォーマットに移行した場合には8.3フォーマットに戻すのを忘れないでください。戻すのに必要なオプションについては構成における構文の変更点を参照ください。 |
8.3が再インストールされたら、 drbdadm または /etc/init.d/drbd start のどちらからでも手動で起動できます。
5.8. デュアルプライマリモードを有効にする
デュアルプライマリモードではリソースが両ノードで同時にプライマリになることができます。これは永続的にも一時的なものとしても加能です。
|
デュアルプライマリモードではリソースが同期レプリケート(プロトコルC)で設定されていることが必要です。そのためレイテンシに過敏となり、WAN環境には適していません。 さらに、両リソースが常にプライマリとなるので、どのようなノード間のネットワーク不通でもスプリットブレインが発生します。 |
5.8.1. 永続的なデュアルプライマリモード
デュアルプライマリモードを有効にするため、リソース設定の net セクションで、
allow-two-primaries オプションを yes に指定します。
resource <resource>
net {
protocol C;
allow-two-primaries yes;
}
disk {
fencing resource-and-stonith;
}
handlers {
fence-peer "...";
unfence-peer "...";
}
...
}そして、両ノード間で設定を同期することを忘れないでください。両ノードで`drbdadm adjust <resource>`を実行してください。
これで drbdadm primary <resource> で、両ノードを同時にプライマリのロールにすることができます。
| 適切なフェンシングポリシーを常に実装してください。フェンシングなしで ‘allow-two-primaries’ を使用することは、フェンシングなしでシングルプライマリを使用するよりも悪い考えです。 |
5.8.2. 一時的なデュアルプライマリモード
通常はシングルプライマリで稼動しているリソースを、一時的にデュアルプライマリモードを有効にするには次のコマンドを実行してください。
# drbdadm net-options --protocol=C --allow-two-primaries <resource>
一時的なデュアルプライマリモードを終えるには、上記と同じコマンドを実行します。ただし、 --allow-two-primaries=no
としてください(また、適切であれば希望するレプリケーションプロトコルにも)。
5.8.3. システム起動時の自動昇格
リソースがデュアルプライマリモードをサポートするように設定されている場合は、システム(またはDRBD)の起動時にリソースを自動的にプライマリロールに切り替わるように設定することをお勧めします。
resource <resource>
startup {
become-primary-on both;
}
...
}スタートアップ時に、 /etc/init.d/drbd システムinitスクリプトはこのオプションを読み込み、これに沿ってリソースを昇格します。
become-primary-on
の方法は避けるべきです。可能であれば、常にクラスタマネージャを使用することをお勧めします。たとえば、Pacemaker管理のDRBD設定を参照してください。Pacemaker
(または他のクラスタマネージャ) 設定では、リソース昇格と降格は常にクラスタ管理システムで操作されるべきです。
|
5.9. オンラインデバイス照合の使用
5.9.1. オンライン照合を有効にする
オンラインデバイス照合はデフォルトでは有効になっていません。有効にする場合は、
/etc/drbd.conf のリソース構成に次の行を追加します。
resource <resource>
net {
verify-alg <algorithm>;
}
...
}<algorithm> は、システムのカーネル構成内のカーネルcrypto
APIでサポートされる任意のメッセージダイジェストアルゴリズムです。通常は sha1 、 md5 、 crc32c から選択します。
既存のリソースに対してこの変更を行う場合は、 drbd.conf を対向ノードと同期し、両方のノードで drbdadm adjust
<resource> を実行します。
5.9.2. オンライン照合の実行
オンライン照合を有効にしたら、次のコマンドでオンライン照合を開始します。
# drbdadm verify <resource>
コマンドを実行すると、DRBDが <resource> に対してオンライン照合を実行します。同期していないブロックを検出した場合は、ブロックに非同期のマークを付け、カーネルログにメッセージを書き込みます。このときにデバイスを使用しているアプリケーションは中断なく動作し続けます。また、リソースロールの切り替えも行うことができます。
照合中に同期していないブロックが検出された場合は、照合の完了後に、次のコマンド使用して再同期できます。
# drbdadm disconnect <resource> # drbdadm connect <resource>
5.9.3. 自動オンライン照合
通常は、オンラインデバイス照合を自動的に実行するほうが便利です。自動化は簡単です。一方のノードに
/etc/cron.d/drbd-verify という名前で、次のような内容のファイルを作成します。
42 0 * * 0 root /sbin/drbdadm verify <resource>これにより、毎週日曜日の午前0時42分に、 cron がデバイス照合を呼び出します。
オンライン照合をすべてのリソースで有効にした場合(たとえば /etc/drbd.conf の common セクションに verify-alg
<algorithm> を追加するなど)には、次のようにできます。
42 0 * * 0 root /sbin/drbdadm verify all5.10. 同期速度の設定
バックグラウンド同期中は同期先のデータとの一貫性が一時的に失われるため、同期をできるだけ早く完了したいと考えるでしょう。ただし、すべての帯域幅がバックグラウンド同期に占有されてしまうと、フォアグラウンドレプリケーションに使用できなくなり、アプリケーションのパフォーマンス低下につながります。これは避ける必要があります。同期用の帯域幅はハードウェアに合わせて設定する必要があります。
| 同期速度をセカンダリノードの最大書き込みスループットを上回る速度に設定しても意味がありません。デバイス同期の速度をどれほど高速に設定しても、セカンダリノードがそのI/Oサブシステムの能力より高速に書き込みを行うことは不可能です。 |
また、同じ理由で、同期速度をレプリケーションネットワークの帯域幅の能力を上回る速度に設定しても意味がありません。
5.10.1. 可変同期速度設定
DRBD 8.4以降、デフォルトは可変レート同期に切り替わりました。このモードでは、DRBDは自動制御のループアルゴリズムを使用して同期速度を常に調整し決定します。このアルゴリズムはフォアグラウンド同期に常に十分な帯域幅を確保し、バックグラウンド同期がフォアグラウンドのI/Oに与える影響を少なくします。
最適な可変レート同期の設定は使用できるネットワーク帯域幅、アプリケーションのI/Oパターンやリンクの輻輳によって変わってきます。理想的な設定はDRBD Proxyの使用有無によっても変わってきます。このDRBDの特徴を最適化するためにコンサルタントを利用するのもよいでしょう。以下は、DRBDを使用した環境での設定の一例です。
resource <resource> {
disk {
c-plan-ahead 200;
c-max-rate 10M;
c-fill-target 15M;
}
}
c-fill-target の初期値は BDP×3 がいいでしょう。BDPとはレプリケーションリンク上の帯域幅遅延積(Bandwidth
Delay Product)です。
|
5.10.2. 永続的な同期速度の設定
テスト目的のために、動的再同期コントローラを無効にし、DRBDを固定の再同期速度に設定することが役立つかもしれません。これは唯一の上限になりますが、ボトルネック(またはアプリケーションIO)がある場合、この速度は達成されません。
リソースがバックグラウンド再同期に使用する最大帯域幅はリソースの resync-rate オプションで指定します。これはリソース設定ファイルの
/etc/drbd.conf の disk セクションに含まれている必要があります。
resource <resource>
disk {
resync-rate 40M;
...
}
...
}毎秒の速度はビット単位ではなくバイトで設定します。デフォルトの単位はキビバイトなので 4096 は 4MiB と解釈されます。
| 経験則では、この数値として使用可能なレプリケーション帯域幅の30%程度が適切です。180MB/sの書き込みスループットを維持できるI/Oサブシステム、および110MB/sのネットワークスループットを維持できるギガビットイーサネットネットワークの場合は、ネットワークが律速要因になります。速度は次のように計算できます。 |
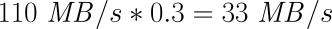
この結果、 rate オプションの推奨値は 33M になります。
一方、最大スループットが80MB/sのI/Oサブシステム、およびギガビットイーサネット接続を使用する場合は、I/Oサブシステムが律速要因になります。速度は次のように計算できます。
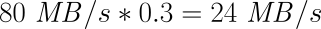
この場合、 rate オプションの推奨値は 24M になります。
5.10.3. 一時的な同期速度の設定
一時的に同期速度を調整したい場合もあるでしょう。たとえば、いずれかのクラスタノードの定期保守を行ったときに、バックグラウンド再同期を高速に実行したい場合などです。また、アプリケーションの書き込み操作が非常に多いときに、バックグラウンド再同期の速度を落して、既存の帯域幅の多くをレプリケーションのために確保したい場合もあります。
たとえば、ギガビットイーサネットリンクのほとんどの帯域幅を再同期に割り当てるには、次のコマンドを実行します:
# drbdadm disk-options --c-plan-ahead=0 --resync-rate=110M <resource>
このコマンドは SyncTarget ノードで実行します。
この一時的な設定を元に戻して、 /etc/drbd.conf で設定された同期速度を再び有効にするには、次のコマンドを実行します。
# drbdadm adjust <resource>
5.11. チェックサムベース同期の設定
チェックサムベース同期はデフォルトでは有効になっていません。有効にする場合は、
/etc/drbd.conf のリソース構成に次の行を追加します。
resource <resource>
net {
csums-alg <algorithm>;
}
...
}<algorithm> は、システムのカーネル構成内のカーネルcrypto
APIでサポートされる任意のメッセージダイジェストアルゴリズムです。通常は sha1 、 md5 、 crc32c から選択します。
既存のリソースに対してこの変更を行う場合は、 drbd.conf を対向ノードと同期し、両方のノードで drbdadm adjust
<resource> を実行します。
5.12. 輻輳ポリシーと中断したレプリケーションの構成
レプリケーション帯域幅が大きく変動する環境(WANレプリケーション設定に典型的)の場合、レプリケーションリンクは時に輻輳します。デフォルト設定では、これはプライマリノードのI/Oのブロックを引き起こし、これは望ましくない場合があります。
その代わりに、進行中の同期を suspend (中断)に設定し、プライマリのデータセットをセカンダリから pull ahead (引き離す)にします。このモードではDRBDはレプリケーションチャネルを開いたままにし、切断モードにはしません。しかし十分な帯域幅が利用できるようになるまで実際にはレプリケートを行いません。
次の例は、DRBD Proxy構成のためのものです。
resource <resource> {
net {
on-congestion pull-ahead;
congestion-fill 2G;
congestion-extents 2000;
...
}
...
}通常は congestion-fill と congestion-extents を pull-ahead
オプションと合わせて設定するのがよい方法でしょう。
congestion-fill の値は以下の値の90%にするとよいでしょう。
-
DRBD Proxy越しの同期の場合の、DRBD Proxyのバッファメモリの割り当て、または
-
DRBD Proxy構成でない環境でのTCPネットワークの送信バッファ
congestion-extents の値は、影響するリソースの al-extents に設定した値の90%がよいでしょう。
5.13. I/Oエラー処理方針の設定
DRBDが下位レベルI/Oエラーを処理する際の方針は、
/etc/drbd.conf の disk セクションの on-io-error オプションで指定します。
resource <resource> {
disk {
on-io-error <strategy>;
...
}
...
}すべてのリソースのグローバルI/Oエラー処理方針を定義したい場合は、これを common セクションで設定します。
<strategy> は、次のいずれかのオプションです。
-
detachこれがデフォルトで、推奨オプションです。下位レベルI/Oエラーが発生すると、DRBDはそのノードの下位デバイスを切り離し、ディスクレスモードで動作を継続します。 -
pass_on上位層にI/Oエラーを通知します。プライマリノードの場合は、マウントされたファイルシステムに通知されます。セカンダリノードの場合は無視されます(セカンダリノードには通知すべき上位層がないため)。 -
call-local-io-errorローカルI/Oエラーハンドラとして定義されたコマンドを呼び出します。このオプションを使うには、対応するlocal-io-errorハンドラをリソースのhandlersセクションに定義する必要があります。local-io-errorで呼び出されるコマンド(またはスクリプト)にI/Oエラー処理を実装するかどうかは管理者の判断です。
DRBDの以前のバージョン(8.0以前)にはもう1つのオプション panic
があり、これを使用すると、ローカルI/Oエラーが発生するたびにカーネルパニックによりノードがクラスタから強制的に削除されました。このオプションは現在は使用できませんが、
local-io-error/call-local-io-error
インタフェースを使用すると同じように動作します。ただし、この動作の意味を十分理解した上で使用してください。ただし、この動作の意味を十分理解した上で使用してください。
|
次のコマンドで、実行中のリソースのI/Oエラー処理方針を再構成することができます。
-
/etc/drbd.d/<resource>.resのリソース構成の編集 -
構成の対向ノードへのコピー
-
両ノードでの
drbdadm adjust <resource>の実行
5.14. レプリケーショントラフィックの整合性チェックを設定
レプリケーショントラフィックの整合性チェックはデフォルトでは有効になっていません。有効にする場合は、
/etc/drbd.conf のリソース構成に次の行を追加します。
resource <resource>
net {
data-integrity-alg <algorithm>;
}
...
}<algorithm> は、システムのカーネル構成内のカーネルcrypto
APIでサポートされる任意のメッセージダイジェストアルゴリズムです。通常は sha1 、 md5 、 crc32c から選択します。
既存のリソースに対してこの変更を行う場合は、 drbd.conf を対向ノードと同期し、両方のノードで drbdadm adjust
<resource> を実行します。
5.15. リソースのサイズ変更
5.15.1. オンラインで拡張する
動作中(オンライン)に下位ブロックデバイスを拡張できる場合は、これらのデバイスをベースとするDRBDデバイスについても動作中にサイズを拡張することができます。その際に、次の2つの条件を満たす必要があります。
-
影響を受けるリソースの下位デバイスが、LVMやEVMSなどの論理ボリューム管理サブシステムによって管理されている。
-
現在、リソースの接続状態が Connected になっている。
両方のノードの下位ブロックデバイスを拡張したら、一方のノードだけがプライマリ状態であることを確認してください。プライマリノードで次のように入力します。
# drbdadm resize <resource>
新しいセクションの同期がトリガーされます。同期はプライマリノードからセカンダリノードへ実行されます。
追加する領域がクリーンな場合には、追加領域の同期を—assume-cleanオプションでスキップできます。
# drbdadm -- --assume-clean resize <resource>
5.15.2. オフラインで拡張する
外部メタデータを使っている場合、DRBD停止中に両ノードの下位ブロックデバイスを拡張すると、新しいサイズが自動的に認識されます。管理者による作業は必要ありません。両方のノードで次にDRBDを起動した際に、DRBDデバイスのサイズが新しいサイズになり、ネットワーク接続が正常に確立します。
DRBDリソースで内部メタデータを使用している場合は、リソースのサイズを変更する前に、メタデータを拡張されるデバイス領域の後ろの方に移動させる必要があります。これを行うには次の手順を実行します。これを行うには次の手順を実行します
| これは高度な手順です。慎重に検討した上で実行してください。 |
-
DRBDリソースを停止します。
# drbdadm down <resource>-
下位ブロックデバイスを拡張する前に、メタデータをテキストファイルに保存します。
# drbdadm dump-md <resource> > /tmp/metadata
各ノードごとにそれぞれのダンプファイルを作成する必要があります。この手順は、両方のノードでそれぞれ実行します。一方のノードのメタデータのダンプを対向ノードにコピーすることは避けてください。これはうまくいきません。
-
両方のノードの下位ブロックデバイスを拡大します。
-
これに合わせて、両方のノードについて、
/tmp/metadataファイルのサイズ情報(la-size-sect)を書き換えます。la-size-sectは、必ずセクタ単位で指定する必要があります。 -
メタデータ領域の再初期化:
# drbdadm create-md <resource>
-
両方のノード上で修正のメタデータをインポートします:
# drbdmeta_cmd=$(drbdadm -d dump-md <resource>)
# ${drbdmeta_cmd/dump-md/restore-md} /tmp/metadata
Valid meta-data in place, overwrite? [need to type 'yes' to confirm]
yes
Successfully restored meta data
この例では bash
パラメータ置換を使用しています。他のシェルの場合、機能する場合もしない場合もあります。現在使用しているシェルが分からない場合は、 SHELL
環境変数を確認してください。
|
-
DRBDリソースを再度有効にします。
# drbdadm up <resource>
-
片側のノードでDRBDリソースをプライマリにします
# drbdadm primary <resource>
-
最後に、拡張したDRBDデバイスを活用するために、ファイルシステムを拡張します。
5.15.3. オンラインで縮小する
| オンラインでの縮小は外部メタデータ使用の場合のみサポートしています。 |
DRBDデバイスを縮小する前に、DRBDの上位層(通常はファイルシステム)を縮小しなければいけません。ファイルシステムが実際に使用している容量を、DRBDが知ることはできないため、データが失われないように注意する必要があります。
| ファイルシステムをオンラインで縮小できるかどうかは、使用しているファイルシステムによって異なります。ほとんどのファイルシステムはオンラインでの縮小をサポートしません。XFSは縮小そのものをサポートしません。 |
オンラインでDRBDを縮小するには、その上位に常駐するファイルシステムを縮小した後に、次のコマンドを実行します。
# drbdadm -- --size=<new-size> resize <resource><new-size> には通常の乗数サフィックス(K、M、Gなど)を使用できます。DRBDを縮小したら、DRBDに含まれるブロックデバイスも縮小できます(デバイスが縮小をサポートする場合)。
5.15.4. オフラインで縮小する
DRBDが停止しているときに下位ブロックデバイスを縮小すると、次にそのブロックデバイスを接続しようとしてもDRBDが拒否します。これは、ブロックデバイスが小さすぎる(外部メタデータを使用する場合)、またはメタデータを見つけられない(内部メタデータを使用する場合)ことが原因です。この問題を回避するには、次の手順を行います(オンライン縮小を使用できない場合)。
| これは高度な手順です。慎重に検討した上で実行してください。 |
-
DRBDがまだ動作している状態で、一方のノードのファイルシステムを縮小します。
-
DRBDリソースを停止します。
# drbdadm down <resource>
-
縮小する前に、メタデータをテキストファイルに保存します。
# drbdadm dump-md <resource> > /tmp/metadata
各ノードごとにそれぞれのダンプファイルを作成する必要があります。この手順は、両方のノードでそれぞれ実行します。一方のノードのメタデータのダンプを対向ノードにコピーすることは避けてください。これはうまくいきません。
-
両方のノードの下位ブロックデバイスを縮小します。
-
これに合わせて、両方のノードについて、
/tmp/metadataファイルのサイズ情報(la-size-sect)を書き換えます。la-size-sectは、必ずセクタ単位で指定する必要があります。 -
内部メタデータを使用している場合は、メタデータ領域を再初期化します(この時点では、縮小によりおそらく内部メタデータが失われています)。
# drbdadm create-md <resource>
-
両方のノード上で修正のメタデータをインポートします:
# drbdmeta_cmd=$(drbdadm -d dump-md <resource>)
# ${drbdmeta_cmd/dump-md/restore-md} /tmp/metadata
Valid meta-data in place, overwrite? [need to type 'yes' to confirm]
yes
Successfully restored meta data
この例では bash
パラメータ置換を使用しています。他のシェルの場合、機能する場合もしない場合もあります。現在使用しているシェルが分からない場合は、 SHELL
環境変数を確認してください。
|
-
DRBDリソースを再度有効にします。
# drbdadm up <resource>
5.16. 下位デバイスのフラッシュを無効にする
| バッテリバックアップ書き込みキャッシュ(BBWC)を備えたデバイスでDRBDを実行している場合にのみ、デバイスのフラッシュを無効にできます。ほとんどのストレージコントローラは、バッテリが消耗すると書き込みキャッシュを自動的に無効にし、バッテリが完全になくなると即時書き込み(ライトスルー)モードに切り替える機能を備えています。このような機能を有効にすることを強くお勧めします。 |
BBWC機能を使用していない、またはバッテリが消耗した状態でBBWCを使用しているときに、DRBDのフラッシュを無効にすると、データが失われるおそれがあります。したがって、これはお勧めできません。
DRBDは下位デバイスのフラッシュを、レプリケートされたデータセットとDRBD独自のメタデータについて、個別に有効と無効を切り替える機能を備えています。この2つのオプションはデフォルトで有効になっています。このオプションのいずれか(または両方)を無効にしたい場合は、DRBD設定ファイル
/etc/drbd.conf の disk セクションで設定できます。
レプリケートされたデータセットのディスクフラッシュを無効にするには、構成に次の行を記述します。
resource <resource>
disk {
disk-flushes no;
...
}
...
}DRBDのメタデータのディスクフラッシュを無効にするには、次の行を記述します。
resource <resource>
disk {
md-flushes no;
...
}
...
}リソースの構成を修正し、また、もちろん両ノードの /etc/drbd.conf
を同期したら、両ノードで次のコマンドを実行して、これらの設定を有効にします。
# drbdadm adjust <resource>
5.17. スプリットブレイン時の動作の設定
5.17.1. スプリットブレインの通知
スプリットブレインが検出されると、DRBD はつねに split-brain
ハンドラを呼び出します(設定されていれば)。このハンドラを設定するには、リソース構成に次の項目を追加します。
resource <resource>
handlers {
split-brain <handler>;
...
}
...
}
<handler> はシステムに存在する任意の実行可能ファイルです。
DRBDディストリビューションでは /usr/lib/drbd/notify-split-brain.sh
という名前のスプリットブレイン対策用のハンドラスクリプトを提供しています。これは指定したアドレスに電子メールで通知を送信するだけのシンプルなものです。
root@localhost (このアドレス宛のメールは実際のシステム管理者に転送されると仮定)にメッセージを送信するようにハンドラを設定するには、
split-brain handler を次のように記述します。
resource <resource>
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
...
}
...
}
実行中のリソースで上記の変更を行い(ノード間で設定ファイルを同期すれば)、後はハンドラを有効にするための他の操作は必要ありません。次にスプリットブレインが発生すると、DRBDが新しく設定したハンドラを呼び出します。
5.17.2. スプリットブレインからの自動復旧ポリシー
| スプリットブレイン(またはその他のシナリオ)に起因するデータ相違問題を自動的に解決するようにDRBDを構成することは、潜在的な 自動データ損失 を構成することを意味します。このことを理解し、そうでない場合は、そのような構成をとらないでください。 |
| むしろフェンシング・ポリシー、統合したクラスタ・マネージャー、および冗長なクラスター・マネージャーの通信リンクを調べて、まずはデータの相違をできるだけ回避するようにしてください。 |
スプリットブレインからの自動復旧ポリシーには、状況に応じた複数のオプションが用意されています。DRBDは、スプリットブレインを検出したときのプライマリロールのノードの数にもとづいてスプリットブレイン回復手続きを適用します。そのために、DRBDはリソース設定ファイルの
net セクションの次のキーワードを読み取ります。
after-sb-0priスプリットブレインが検出されたときに両ノードともセカンダリロールの場合に適用されるポリシーを定義します。次のキーワードを指定できます。
-
disconnect: 自動復旧は実行されません。split-brainハンドラスクリプト(設定されている場合)を呼び出し、コネクションを切断して切断モードで続行します。 -
discard-younger-primary: 最後にプライマリロールだったホストに加えられた変更内容を破棄してロールバックします。 -
discard-least-changes: 変更が少なかったほうのホストの変更内容を破棄してロールバックします。 -
discard-zero-changes: 変更がなかったホストがある場合は、他方に加えられたすべての変更内容を適用して続行します。
after-sb-1priスプリットブレインが検出されたときにどちらか1つのノードがプライマリロールである場合に適用されるポリシーを定義します。次のキーワードを指定できます。次のキーワードを指定できます。
-
disconnect:after-sb-0priと同様に、split-brainハンドラスクリプト(構成されている場合)を呼び出し、コネクションを切断して切断モードで続行します。 -
consensus:after-sb-0priで設定したものと同じ復旧ポリシーが適用されます。これらのポリシーを適用した後で、スプリットブレインの犠牲ノードを選択できる場合は自動的に解決します。それ以外の場合は、disconnectを指定した場合と同様に動作します。 -
call-pri-lost-after-sb:after-sb-0priで指定した復旧ポリシーが適用されます。これらのポリシーを適用した後で、スプリットブレインの犠牲ノードを選択できる場合は、犠牲ノードでpri-lost-after-sbハンドラを起動します。このハンドラはhandlersセクションで設定する必要があります。また、クラスタからノードを強制的に削除します。 -
discard-secondary: 現在のセカンダリロールのホストを、スプリットブレインの犠牲ノードにします。
after-sb-2pri.スプリットブレインが検出されたときに両ノードともプライマリロールである場合に適用されるポリシーを定義します。このオプションは
after-sb-1pri と同じキーワードを受け入れます。ただし、 discard-secondary と consensus
は除きます。
上記の3つのオプションで、DRBDは追加のキーワードも認識しますが、これらはめったに使用されないためここでは省略します。ここで取り上げた以外のスプリットブレイン復旧キーワードについては、
drbd.conf マニュアルページを参照してください。
|
たとえば、デュアルプライマリモードでGFSまたはOCFS2ファイルシステムのブロックデバイスとして機能するリソースの場合、次のように復旧ポリシーを定義できます。
resource <resource> {
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh root"
...
}
net {
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
...
}
...
}
5.18. 3ノード構成の作成
3ノード構成では、1つのDRBDデバイスを別のデバイスの上にスタック(積み重ね)します。
5.18.1. デバイススタックの検討事項
3ノード構成では次のような事項に注意する必要があります。
-
スタックデバイスがアクティブなデバイスです。1つのDRBDデバイス
/dev/drbd0が構成され、その上位にスタックデバイス/dev/drbd10があるとします。この場合は、/dev/drbd10がマウントされて使用されるデバイスになります。 -
下位のDRBDデバイスおよびスタックDRBDデバイス(上位DRBDデバイス)の両方にそれぞれメタデータが存在します。上位DRBDデバイスには、必ず内部メタデータを使用してください。このため、3ノード構成時の使用可能なディスク領域は、2ノード構成に比べてわずかに小さくなります。
-
スタックされた上位デバイスを実行するには、下位のデバイスがプライマリロールになっている必要があります。
-
バックアップノードにデータを同期するには、アクティブなノードのスタックデバイスがプライマリモードで動作している必要があります。
5.18.2. スタックリソースの設定
次の例では ‘alice’ 、 ‘bob’ 、 ‘charlie’ という名前のノードがあり、 ‘alice’ と ‘bob’ が2ノードクラスタを構成し、 ‘charlie’ がバックアップノードになっています。
resource r0 {
net {
protocol C;
}
on alice {
device /dev/drbd0;
disk /dev/sda6;
address 10.0.0.1:7788;
meta-disk internal;
}
on bob {
device /dev/drbd0;
disk /dev/sda6;
address 10.0.0.2:7788;
meta-disk internal;
}
}
resource r0-U {
net {
protocol A;
}
stacked-on-top-of r0 {
device /dev/drbd10;
address 192.168.42.1:7788;
}
on charlie {
device /dev/drbd10;
disk /dev/hda6;
address 192.168.42.2:7788; # Public IP of the backup node
meta-disk internal;
}
}他の drbd.conf
設定ファイルと同様に、この設定ファイルもクラスタのすべてのノード(この場合は3つ)に配布する必要があります。非スタックリソース構成にはない次のキーワードにご注意ください。
stacked-on-top-ofこの情報により、DRBDに含まれるリソースがスタックリソースであることをDRBDに知らせます。これは、非スタックリソース構成ににある2つの on
セクションのいずれかと置き換えます。下位レベルリソースには stacked-on-top-of を使用しないでください。
| スタックリソースにProtocol Aを使用することは必須ではありません。アプリケーションに応じて任意のDRBDのレプリケーションプロトコルを選択できます。 |
5.18.3. スタックリソースを有効にする
スタックリソースを有効にするには、まず、下位レベルリソースを有効にしてどちらか一方をプライマリに昇格します。
drbdadm up r0 drbdadm primary r0
非スタックリソースと同様に、スタックリソースの場合もDRBDメタデータを作成する必要があります。次のコマンドで実行します。
# drbdadm create-md --stacked r0-U
次に、スタックリソースを有効にします。
# drbdadm up --stacked r0-U # drbdadm primary --stacked r0-U
この後でバックアップノードのリソースを起動し、3ノードレプリケーションを有効にします。:
# drbdadm create-md r0-U # drbdadm up r0-U
クラスタ管理システムを使えばスタックリソースの管理を自動化できます。Pacemakerクラスタ管理フレームワークで管理する方法については、PacemakerクラスタでスタックDRBDリソースを使用するを参照してください。
5.19. Using DRBD Proxy
5.19.1. DRBD Proxy配備に関する検討事項
DRBD Proxyプロセスは、DRBDが設定されているマシン上に直接配置するか、個別の専用サーバに配置することができます。DRBD Proxyインスタンスは、複数のノードの複数のDRBDデバイスのプロキシとして機能することができます。
DRBD ProxyはDRBDに対して完全に透過的です。通常は大量のデータパケットがDRBD
Proxyを含む転送経路に溜まるため、アクティビティログがかなり大きくなります。これは、プライマリノードのクラッシュ後の長い再同期の実行を引き起こす可能性があるので、それはDRBDの
csums-alg 設定を有効にすることをお勧めします。
5.19.2. インストール
DRBD Proxyを入手するには、(日本では)サイオステクノロジー株式会社またはその販売代理店に連絡してください。特別な理由がない限り、常に最新バージョンのDRBD Proxyを使用してください。
DebianとDebianベースのシステム上でDRBD Proxyをインストールするには(DRBD Proxyのバージョンとアーキテクチャは、ターゲットのアーキテクチャに合わせてください)、dpkgを次のように使用します。
# dpkg -i drbd-proxy_3.0.0_amd64.deb
RPMベースのシステム(SLESやRedhat)にDRBD Proxyをインストールする場合は、次のコマンドを使用します(DRBD Proxyのバージョンとアーキテクチャは、ターゲットのアーキテクチャに合わせてください)。
# rpm -i drbd-proxy-3.0-3.0.0-1.x86_64.rpm
DRBD Proxyの設定にはdrbdadmが必要なので、これもインストールします。
DRBD Proxyバイナリだけでなく、 /etc/init.d に通常に入る起動スクリプトもインストールします。DRBD
Proxyを起動/停止するには、通常はこの起動スクリプトを使ってください。このスクリプトは単に起動/停止するだけでなく、 drbdadm
を使ってDRBD Proxyの動作も設定します。
5.19.3. ライセンスファイル
DRBD Proxyの実行には、ライセンスファイルが必要です。DRBD
Proxyを実行したいマシンにライセンスファイルを設定してください。このファイルは drbd-proxy.license と呼ばれ、対象マシンの
/etc ディレクトリにコピーされ、また drbdpxy ユーザ/グループに所有されている必要があります。
# cp drbd-proxy.license /etc/
5.19.4. 設定
DRBD ProxyはDRBDのメイン設定ファイルで設定します。設定は、追加のオプションセクション proxy とホストセクション内の proxy
on セクションで行います。
DRBDノードで直接実行されるプロキシのDRBD Proxyの設定例を次に示します。
resource r0 {
net {
protocol A;
}
device minor 0;
disk /dev/sdb1;
meta-disk /dev/sdb2;
proxy {
memlimit 100M;
plugin {
zlib level 9;
}
}
on alice {
address 127.0.0.1:7789;
proxy on alice {
inside 127.0.0.1:7788;
outside 192.168.23.1:7788;
}
}
on bob {
address 127.0.0.1:7789;
proxy on bob {
inside 127.0.0.1:7788;
outside 192.168.23.2:7788;
}
}
}inside IPアドレスはDRBDとDRBD Proxyとの通信に使用し、 outside IPアドレスはプロキシ間の通信に使用します。
5.19.5. DRBD Proxyの制御
drbdadm には proxy-up および proxy-down サブコマンドがあり、名前付きDRBDリソースのローカルDRBD
Proxyプロセスとの接続を設定したり削除したりできます。これらのコマンドは、 /etc/init.d/drbdproxy が実装する
start および stop アクションによって使用されます。
DRBD Proxyには drbd-proxy-ctl
という下位レベル構成ツールがあります。このツールをオプションを指定せずに呼び出した場合は、対話型モードで動作します。
対話型モードをにせずコマンドを直接渡すには、 -c パラメータをコマンドに続けて使用します。
使用可能なコマンドを表示するには次のようにします。
# drbd-proxy-ctl -c "help"
コマンドの周りのダブルクォートは読み飛ばされる点に注意ください。
add connection <name> <listen-lan-ip>:<port> <remote-proxy-ip>:<port>
<local-proxy-wan-ip>:<port> <local-drbd-ip>:<port>
Creates a communication path between two DRBD instances.
set memlimit <name> <memlimit-in-bytes>
Sets memlimit for connection <name>
del connection <name>
Deletes communication path named name.
show
Shows currently configured communication paths.
show memusage
Shows memory usage of each connection.
show [h]subconnections
Shows currently established individual connections
together with some stats. With h outputs bytes in human
readable format.
show [h]connections
Shows currently configured connections and their states
With h outputs bytes in human readable format.
shutdown
Shuts down the drbd-proxy program. Attention: this
unconditionally terminates any DRBD connections running.
Examples:
drbd-proxy-ctl -c "list hconnections"
prints configured connections and their status to stdout
Note that the quotes are required.
drbd-proxy-ctl -c "list subconnections" | cut -f 2,9,13
prints some more detailed info about the individual connections
watch -n 1 'drbd-proxy-ctl -c "show memusage"'
monitors memory usage.
Note that the quotes are required as listed above.上記のコマンドは、UID 0 (つまり root
ユーザ)でのみ受け入れられますが、どのユーザでも使える情報収集のコマンドがあります(unixのパーミッションが
/var/run/drbd-proxy/drbd-proxy-ctl.socket
のプロキシソケットへのアクセスを許可していれば)。権限の設定については /etc/init.d/drbdproxy
のinitスクリプトを参照してください。
print details This prints detailed statistics for the currently active connections. Can be used for monitoring, as this is the only command that may be sent by a user with UID quit Exits the client program (closes control connection).
5.19.6. DRBD Proxyプラグインについて
DRBD proxy 3.0以降のプロキシではWANコネクション用のプラグインを使用できます。 現在使用できるプラグインは zlib と
lzma です。
zlib プラグインはGZIPアルゴリズムを圧縮に使っています。CPU使用量が低いのが利点です。
lzma
プラグインはliblzma2ライブラリを使います。数百MiBの辞書を使って、小さな変更であっても非常に効率的な繰り返しデータの差分符号化を行います。
lzma はより多くCPUとメモリを必要としますが、 zlib よりも高い圧縮率になります。 lzma
プラグインはライセンスで有効化されてる必要があります。
CPU (速度、スレッド数)、メモリ、インプットと有効なアウトプット帯域幅に応じたプラグインの推奨構成については、サイオステクノロジーに相談してください。
proxy セクションの古い compression on は使用されておらず、次期リリースではなくなる予定です。 現在は zlib
level 9 で扱っています。
5.19.7. WANサイドの帯域幅制限を使用する
DRBD Proxyの実験的なbwlimitオプションは壊れています。DRBD上のアプリケーションがIOをブロックする可能性があるため、使用しないでください。これはいずれ削除されます。
代わりにLinuxカーネルのトラフィック制御フレームワークを使用して、WAN側でプロキシが消費する帯域幅を制限します。
次の例では、対抗ノードのインターフェイス名、送信元ポート、およびIPアドレスを置き換えて使用します。
# tc qdisc add dev eth0 root handle 1: htb default 1
# tc class add dev eth0 parent 1: classid 1:1 htb rate 1gbit
# tc class add dev eth0 parent 1:1 classid 1:10 htb rate 500kbit
# tc filter add dev eth0 parent 1: protocol ip prio 16 u32 \
match ip sport 7000 0xffff \
match ip dst 192.168.47.11 flowid 1:10
# tc filter add dev eth0 parent 1: protocol ip prio 16 u32 \
match ip dport 7000 0xffff \
match ip dst 192.168.47.11 flowid 1:10
以下のコマンドで帯域制限設定を削除できます。
# tc qdisc del dev eth0 root handle 1
5.19.8. トラブルシューティング
DRBD proxyのログはsyslogの LOG_DAEMON ファシリティに記録されます。通常ログは /var/log/daemon.log
に記録されます。
DRBD Proxyでデバッグモードを有効にするには次のようにします。
# drbd-proxy-ctl -c 'set loglevel debug'
たとえば、DRBD Proxyが接続に失敗すると、 Rejecting connection because I can’t connect on
the other side
というようなメッセージがログに記録されます。その場合は、DRBDが(スタンドアローンモードでなく)両方のノードで動作していて、両方ノードでプロキシが動作していることを確認してください。また、両方のノードで設定値を確認してください。
6. トラブルシューティングとエラーからの回復
この章では、ハードウェアやシステムに障害が発生した場合に必要な手順について説明します。
6.1. ハードドライブの障害の場合
ハードドライブの障害への対処方法は、DRBDがディスクI/Oエラーを処理する方法(ディスクエラー処理ストラテジーを参照)、また設定されているメタデータの種類(DRBDメタデータを参照)によって異なります。
| ほとんどの場合、ここで取り上げる手順はDRBDを直接物理ハードドライブ上で実行している場合にのみ適用されます。次に示す層の上でDRBDを実行している場合には通常は適用されません。 |
-
MDソフトウェアRAIDセット(この場合は
mdadmを使用してドライブ交換を管理) -
デバイスマッパRAID(`dmraid`を使用)
-
ハードウェアRAID機器(障害が発生したドライブの扱いについては、ベンダの指示に従う)
-
一部の非標準デバイスマッパ仮想ブロックデバイス(デバイスマッパのマニュアルを参照)
6.1.1. 手動でDRBDをハードドライブから切り離す
DRBDがI/Oエラーを渡すように設定されている場合(非推奨)、まずDRBDリソースを切り離すとよいでしょう。つまり補助記憶装置から切り離します。
drbdadm detach <resource>
`drbdadm dstate`コマンドを実行して、リソースがディスクレスモードになったことを確認します。
drbdadm dstate <resource> Diskless/UpToDate
ディスク障害がプライマリノードで発生した場合、スイッチオーバーと、この手順を組み合わせることもできます。
6.1.2. I/Oエラー時の自動切り離し
DRBDがI/Oエラー時に自動的に切り離しを行うように設定(推奨オプション)されている場合、手動での操作なしで、DRBDはすでにリソースを下位ストレージから自動的に切り離しているはずです。その場合でも
drbdadm dstate コマンドを使用して、リソースが実際にディスクレスモードで実行されているか確認します。
6.1.3. 障害が発生したディスクの交換(内部メタデータを使用している場合)
内部メタデータを使用している場合、新しいハードディスクでDRBDデバイスを再構成するだけで十分です。交換したハードディスクのデバイス名が交換前と異なる場合は、DRBD設定ファイルを適切に変更してください。
新しいメタデータを作成してから、リソースを再接続します。
drbdadm create-md <resource> v08 Magic number not found Writing meta data... initialising activity log NOT initializing bitmap New drbd meta data block sucessfully created. drbdadm attach <resource>
新しいハードディスクの完全同期が瞬時に自動的に始まります。通常のバックグラウンド同期と同様、同期の進行状況を /proc/drbd
で監視することができます。
6.1.4. 障害の発生したディスクの交換(外部メタデータを使用している場合)
外部メタデータを使用している場合でも、手順は基本的に同じです。ただし、DRBDだけではハードドライブが交換されたことを認識できないため、追加の手順が必要です。
drbdadm create-md <resource> v08 Magic number not found Writing meta data... initialising activity log NOT initializing bitmap New drbd meta data block sucessfully created. drbdadm attach <resource> drbdadm invalidate <resource>
上記の drbdadm invalidate コマンドが同期をトリガーします。この場合でも、同期の進行状況は /proc/drbd
で確認できます。
6.2. ノード障害に対処する
DRBDが(実際のハードウェア障害であれ手動による介入であれ)対向ノードがダウンしていることを検出すると、DRBDは自身の接続状態を Connected から WFConnection に変更し、対向ノードが再び現れるのを待ちます。その後、DRBDリソースは切断モードで動作します。切断モードでは、リソースおよびリソースに関連付けられたブロックデバイスが完全に利用可能で、必要に応じて昇格したり降格したりします。ただし、ブロックの変更は対向ノードにレプリケートされません。切断中に変更されたブロックについての内部情報はDRBDが格納します。
6.2.1. 一時的なセカンダリノードの障害に対処する
現時点でセカンダリロールでリソースを持っているノードに一時的に障害が生じた場合(たとえばメモリ交換で直るようなメモリの問題)には、障害が発生したノードを修復してオンラインに戻すだけで十分です。修正したノードを起動すると、ノード間の接続が再確立され、停止中にプライマリノードに加えられた変更内容すべてがセカンダリノードに同期されます。
| この時点で、DRBDの再同期アルゴリズムの性質により、セカンダリノードのリソースの一貫性が一時的に失われます。この短時間の再同期の間は、対向ホストが使用できない場合でも、セカンダリノードをプライマリロールに切り替えることができません。したがって、セカンダリノードの実際のダウンタイムとその後の再同期の間は、クラスタが冗長性を持たない期間になります。 |
6.2.2. 一時的なプライマリノードの障害に対処する
DRBDからみると、プライマリノードの障害とセカンダリノードの障害はほぼ同じです。生き残ったノードが対向ノードの障害を検出し、切断モードに切り替わります。DRBDは生き残ったノードをプライマリロールに昇格しません。昇格はクラスタ管理システムが管理します。
障害が発生したノードが修復されてクラスタに戻る際に、セカンダリロールになります。すでに述べたように、それ以上の手動による介入は必要ありません。このときもDRBDはリソースのロールを元に戻しません。変更を行うように設定されている場合は、クラス管理システムがこの変更を行います。
プライマリノードに障害が発生すると、DRBDはアクティビティログというメカニズムによってブロックデバイスの整合性を確保します。詳細はアクティビティログを参照してください。
6.2.3. 永続的なノード障害に対処する
ノードに回復不能な問題が発生した場合やノードが永久的に破損した場合は、次の手順を行う必要があります。
-
障害が発生したハードウェアを同様のパフォーマンスとディスク容量を持つハードウェアと交換します。
| 障害が発生したノードを、それよりパフォーマンスが低いものと置き換えることも可能ですが、お勧めはできません。障害が発生したノードを、それよりディスク容量が小さいものと置き換えることはできません。この場合、DRBDを置き換えたノードに接続できません。 |
この時点で、デバイスの完全同期を手動で開始する必要はありません。生き残ったプライマリノードへの接続時に、同期が自動的に開始します。
6.3. スプリットブレインからの手動回復
ノード間の接続が可能になると、ノード間で初期ハンドシェイクのプロトコルが交換されます。この時点でDRBDはスプリットブレインが発生したかどうかを判断できます。両方のノードがプライマリロールであるか、もしくは切断中に両方がプライマリロールになったことを検出すると、DRBDは即座にレプリケーション接続を切断します。その場合、システムログにたとえば次のようなメッセージが記録されます。
Split-Brain detected, dropping connection!
スプリットブレインが検出されると、1つのノードは常に StandAlone の状態でリソースを保持します。もう一方のノードもまた StandAlone 状態になるか(両方のノードが同時にスプリットブレインを検出した場合)、または WFConnection 状態になります(一方のノードがスプリットブレインを検出する前に対向ノードが切断をした場合)。
DRBDがスプリットブレインから自動的に回復するように設定されていない場合は、この時点で手動で介入して、変更内容を破棄するほうのノードを選択する必要があります。(このノードはスプリットブレインの犠牲ノードと呼ばれる)。この介入は次のコマンドで行います。
|
スプリットブレインの犠牲ノードは StandAlone の接続状態である必要があり、そうでなければ次のコマンドはエラーを返してきます。次のコマンド実行で確実にstandaloneにできます。 drbdadm disconnect <resource> |
drbdadm secondary <resource> drbdadm connect --discard-my-data <resource>
他方のノード(スプリットブレインの生存ノード)の接続状態も StandAlone の場合には、次のコマンド実行します。
drbdadm connect <resource>
ノードがすでに WFConnection 状態の場合は自動的に再接続するので、この手順は省略できます。
スプリットブレインの影響を受けるリソースがスタックリソースの場合は、単に drbdadm ではなく、
drbdadm --stacked を使用します。
接続すると、スプリットブレインの犠牲ノードの接続状態がすぐに SyncTarget に変化し、残ったプライマリノードによって変更内容が上書きされます。
| スプリットブレインの犠牲ノードは、デバイスのフル同期の対象にはなりません。代わりに、ローカル側での変更がロールバックされ、スプリットブレインの生存ノードに対して加えられた変更が犠牲ノードに伝播されます。 |
再同期が完了すると、スプリットブレインが解決したとみなされ、2つのノードが再び完全に一致した冗長レプリケーションストレージシステムとして機能します。
DRBDとアプリケーションの組み合わせ
7. DRBDとPacemakerクラスタ
PacemakerクラスタスタックとDRBDの組み合わせは、もっとも一般的なDRBDの使いみちです。Pacemakerは、さまざまな使用シナリオにおいてDRBDを非常に強力なものにするアプリケーションの1つです。
7.1. Pacemakerの基礎
Pacemakerは、Linuxのプラットフォーム用の、高度で機能豊富な、幅広く活用されているクラスタリソースマネージャです。豊富なマニュアルが用意されています。この章を理解するために、以下のドキュメントを読むことを強くお勧めします。
-
Clusters From Scratch高可用性クラスタ構築ステップバイステップガイド
-
CRM CLI (command line interface) toolCRMのシェルやシンプルかつ直感的なコマンドラインインタフェースのマニュアル
-
Pacemaker Configuration ExplainedPacemakerの背景にあるコンセプトや設計を説明している参考ドキュメント
7.2. クラスタ構成にDRBDのサービスを追加する
ここでは、Pacemakerクラスタで、DRBDのサービスを有効にする方法を説明します。
| DRBD OCFリソースエージェントを採用する場合は、DRBDに関するすべての操作、すなわち起動、終了、昇格、降格はOCFリソースエージェントに完全に委ねるべきです。つまり、DRBDの起動スクリプトを無効にしてください。 |
chkconfig drbd off
ocf:linbit:drbd
OCFリソースエージェントはマスター/スレーブ機能をサポートするので、Pacemakerは複数のノードでDRBDリソースを開始して監視でき、必要に応じて昇格と降格をコントロールできます。ただし、Pacemakerをシャットダウンした場合やノードをスタンバイモードにすると、これらの影響を受けるノードの
drbd リソースは停止されます。
DRBDに同梱されるOCFリソースエージェントは、 linbit プロバイダに属しているため、
/usr/lib/ocf/resource.d/linbit/drbd としてインストールされます。heartbeat
2に同梱されている古いリソースエージェントは、 heartbeat プロバイダを使用して、
/usr/lib/ocf/resource.d/heartbeat/drbd にインストールされています。古いOCF RAの使用はお勧めできません。
|
drbd OCFリソースエージェントを使用して、Pacemaker
CRMクラスタでMySQLデータベース用のDRBDを使用する構成を有効にするには、必要なリソースを定義し、昇格したDRBDリソースのみでサービスが開始するようにPacemaker制約を設定する必要があります。これには、次の例で説明するようにcrmシェルを使用します。これには、次の例で説明するように
crm シェルを使用します。
crm configure
crm(live)configure# primitive drbd_mysql ocf:linbit:drbd \
params drbd_resource="mysql" \
op monitor interval="29s" role="Master" \
op monitor interval="31s" role="Slave"
crm(live)configure# ms ms_drbd_mysql drbd_mysql \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
crm(live)configure# primitive fs_mysql ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/mysql" \
directory="/var/lib/mysql" fstype="ext3"
crm(live)configure# primitive ip_mysql ocf:heartbeat:IPaddr2 \
params ip="10.9.42.1" nic="eth0"
crm(live)configure# primitive mysqld lsb:mysqld
crm(live)configure# group mysql fs_mysql ip_mysql mysqld
crm(live)configure# colocation mysql_on_drbd \
inf: mysql ms_drbd_mysql:Master
crm(live)configure# order mysql_after_drbd \
inf: ms_drbd_mysql:promote mysql:start
crm(live)configure# commit
crm(live)configure# exit
bye
これで設定が有効になります。DRBDリソースを昇格させるノードをPacemakerが選択し、同じノードでDRBDで保護されたリソースグループを開始します。
7.3. Pacemakerクラスタでリソースレベルのフェンシングを使用する
ここでは、DRBDのレプリケーションリンクが遮断された場合に、Pacemakerが drbd
マスター/スレーブリソースを昇格させないようにするために必要な手順の概要を説明します。これにより、Pacemakerが古いデータでサービスを開始し、プロセスでの不要な「タイムワープ」の原因になることが回避されます。
DRBD用のリソースレベルのフェンシングを有効にするには、リソース設定で次の行を追加する必要があります。
resource <resource> {
disk {
fencing resource-only;
...
}
}同時に、使用するクラスタインフラストラクチャによっては handlers セクションも変更しなければなりません。
-
Heartbeatを使用したPacemakerクラスタは
dopdでのリソースレベルフェンシングで説明している設定を使用できます。 -
CorosyncとHeartbeatを使用したクラスタはCIB (Cluster Information Base)を使ったリソースレベルフェンシングで説明されている機能を使うことがきます。
最低でも2つの独立したクラスタ通信チャネルを設定しなければ、この機能は正しく動作しません。HeartbeatベースのPacemakerクラスタでは
ha.cf 設定ファイルに最低2つのクラスタ通信のリンクを定義する必要があります。Corosyncクラスタでは最低2つの冗長リングを
corosync.conf に記載しなければいけません。
|
7.3.1. dopd でのリソースレベルフェンシング
Heartbeatを使用したPacemakerクラスタでは、DRBDは DRBD outdate-peer
daemon 、または略して dopd と呼ばれるリソースレベルのフェンシング機能を使用できます。
dopd 用のHeartbeat設定
dopdを有効にするには、次の行を
/etc/ha.d/ha.cf ファイルに追加します。
respawn hacluster /usr/lib/heartbeat/dopd
apiauth dopd gid=haclient uid=hacluster使用するディストリビューションに応じて dopd のパスを調整する必要があります。一部のディストリビューションとアーキテクチャでは、正しいパスが
/usr/lib64/heartbeat/dopd になります。
変更を行い ha.cf を対向ノードにコピーをしたら、設定ファイルを読み込むためにPacemakerをメンテナンスモードにして
/etc/init.d/heartbeat reload を実行します。その後、 dopd プロセスが動作していることを確認できるでしょう。
このプロセスを確認するには、 ps ax | grep dopd を実行するか、 killall -0 dopd を使用します。
|
dopd のDRBD設定
dopd が起動したら、DRBDリソース設定にアイテムを追加します。
resource <resource> {
handlers {
fence-peer "/usr/lib/heartbeat/drbd-peer-outdater -t 5";
...
}
disk {
fencing resource-only;
...
}
...
}dopd と同様に、システムのアーキテクチャやディストリビューションによっては drbd-peer-outdater バイナリは
/usr/lib64/heartbeat に配置されます。
最後に、 drbd.conf を対向ノードにコピーし、 drbdadm adjust resource
を実行して、リソースを再構成し、変更内容を反映します。
dopd 機能のテスト
設定した dopd
が正しく動作しているか確認するためには、Heartbeatサービスが正常に動作しているときに、構成済みの接続されているリソースのレプリケーションリンクを遮断します。ネットワークリンクを物理的に取り外すことで簡単にできますが、少々強引ではあります。あるいは、一時的に
iptables ルールを追加して、DRBD用TCPトラフィックを遮断します。
すると、リソースの接続状態が Connected
から WFConnection
に変わります。数秒後にディスク状態がindexterm:Outdated/DUnknownに変化します。これで dopd
が機能していることを確認できます。
これ以降は、古いリソースをプライマリロールに切り替えようとしても失敗します。
物理リンクを接続するか、一時的な iptables ルールを削除してネットワーク接続を再確立すると、接続状態が Connected
に変化し、すぐに SyncTarget
になります(ネットワーク遮断中に、プライマリノードで変化が起こった場合)。同期が終了すると、無効状態であったリソースに再度 UpToDate のマークが付きます。
7.3.2. CIB (Cluster Information Base)を使ったリソースレベルフェンシング
Pacemaker用のリソースレベルフェンシングを有効にするには、 drbd.conf の2つのオプション設定をする必要があります。
resource <resource> {
disk {
fencing resource-only;
...
}
handlers {
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
after-resync-target "/usr/lib/drbd/crm-unfence-peer.sh";
...
}
...
}DRBDレプリケーションリンクが切断された場合には crm-fence-peer.sh
スクリプトがクラスタ管理システムに連絡し、このDRBDリソースに関連付けられたPacemakerのマスター/スレーブリソースが決定され、現在アクティブなノード以外のすべてのノードでマスター/スレーブリソースが昇格されることがないようにします。逆に、接続が再確立してDRBDが同期プロセスが完了すると、この制約は解除され、クラスタ管理システムは再び任意のノードのリソースを自由に昇格させることができます。
7.4. PacemakerクラスタでスタックDRBDリソースを使用する
スタックリソースでは、マルチノードクラスタの多重冗長性のために、あるいはオフサイトのディザスタリカバリ機能を確立するためにDRBDを使用できます。このセクションでは、そのような構成におけるDRBDおよびPacemakerの設定方法について説明します。
7.4.1. オフサイトディザスタリカバリ機能をPacemakerクラスタに追加する
この構成シナリオでは、1つのサイトの2ノードの高可用性クラスタと、一般的には別のサイトに設置する独立した1つのノードについて説明します。第3のノードは、ディザスタリカバリノードとして機能するスタンドアロンサーバです。次の図で概念を説明します。次の図で概念を説明します。
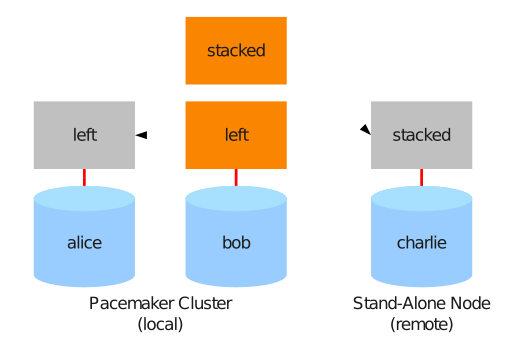
この例では ‘alice’ と ‘bob’ が2ノードのPacemakerクラスタを構成し、 ‘charlie’ はPacemakerに管理されないオフサイトのノードです。
このような構成を作成するには、3ノード構成の作成の説明に従って、まずDRBDリソースを設定および初期を行います。そして、次のCRM構成でPacemakerを設定します。
primitive p_drbd_r0 ocf:linbit:drbd \
params drbd_resource="r0"
primitive p_drbd_r0-U ocf:linbit:drbd \
params drbd_resource="r0-U"
primitive p_ip_stacked ocf:heartbeat:IPaddr2 \
params ip="192.168.42.1" nic="eth0"
ms ms_drbd_r0 p_drbd_r0 \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true" globally-unique="false"
ms ms_drbd_r0-U p_drbd_r0-U \
meta master-max="1" clone-max="1" \
clone-node-max="1" master-node-max="1" \
notify="true" globally-unique="false"
colocation c_drbd_r0-U_on_drbd_r0 \
inf: ms_drbd_r0-U ms_drbd_r0:Master
colocation c_drbd_r0-U_on_ip \
inf: ms_drbd_r0-U p_ip_stacked
colocation c_ip_on_r0_master \
inf: p_ip_stacked ms_drbd_r0:Master
order o_ip_before_r0-U \
inf: p_ip_stacked ms_drbd_r0-U:start
order o_drbd_r0_before_r0-U \
inf: ms_drbd_r0:promote ms_drbd_r0-U:startこの構成を /tmp/crm.txt という一時ファイルに保存し、次のコマンドで現在のクラスタにインポートします。
crm configure < /tmp/crm.txt
この設定により、次の操作が正しい順序で ‘alice’ と ‘bob’ クラスタで行われます。
-
PacemakerはDRBDリソース
r0を両クラスタノードで開始し、1つのノードをマスター(DRBD Primary)ロールに昇格させます。 -
PacemakerはIPアドレス192.168.42.1の、第3ノードへのレプリケーションに使用するスタックリソースを開始します。これは、
r0DRBDリソースのマスターロールに昇格したノードで行われます。 -
r0がプライマリになっていて、かつ、r0-Uのレプリケーション用IPアドレスを持つノードで、Pacemakerはオフサイトノードに接続およびレプリケートを行うr0-UDRBDリソースを開始します。 -
最後に、Pacemakerが
r0-Uリソースもプライマリロールに昇格させるため、ディザスタリカバリノードとのレプリケーションが始まります。
このように、このPacemaker構成では、クラスタノード間だけではなく第3のオフサイトノードでも完全なデータ冗長性が確保されます。
| このタイプの構成は、DRBD Proxyを併用するのが一般的です。 |
7.4.2. スタックリソースを使って、Pacemakerクラスタの4ノード冗長化を実現する
この構成では、全部で3つのDRBDリソース(2つの非スタック、1つのスタック)を使って、4方向ストレージの冗長化を実現します。4ノードクラスタの意義と目的は、3ノードまで障害が発生しても、可用なサービスを提供し続けられるということです。
次の例で概念を説明します。
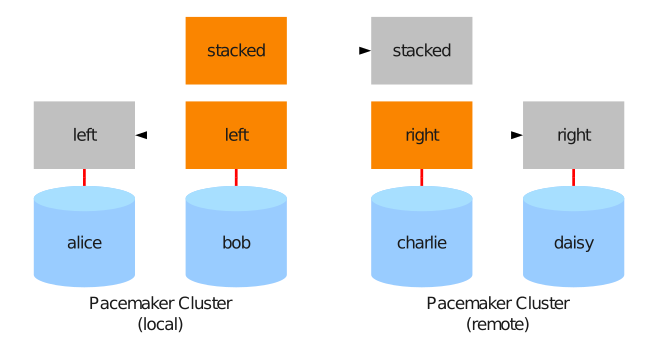
この例では、 ‘alice’ 、 ‘bob’ 、 ‘charlie’ 、 ‘daisy’ が2セットの2ノードPacemakerクラスタを構成しています。 ‘alice’ と ‘bob’ は ‘left’ という名前のクラスタを構成し、互いにDRBDリソースを使ってデータをレプリケートします。一方 ‘charlie’ と ‘daisy’ も同様に、 ‘right’ という名前の別のDRBDリソースでレプリケートします。3番目に、DRBDリソースをスタックし、2つのクラスタを接続します。
| Pacemakerバージョン1.0.5のPacemakerクラスタの制限により、CIBバリデーションを有効にしたままで4ノードクラスタをつくることはできません。CIBバリデーションは汎用的に使うのには向かない特殊な高度な処理です。これは、今後のペースメーカーのリリースで解決されることが予想されます。 |
このような構成を作成するには、3ノード構成の作成の説明に従って、まずDRBDリソースを設定して初期化します(ただし、ローカルがクラスタになるだけでなく、リモート側にもクラスタになる点が異なります)。そして、次のCRM構成でPacemakerを設定し、 ‘left’ クラスタを開始します。
primitive p_drbd_left ocf:linbit:drbd \
params drbd_resource="left"
primitive p_drbd_stacked ocf:linbit:drbd \
params drbd_resource="stacked"
primitive p_ip_stacked_left ocf:heartbeat:IPaddr2 \
params ip="10.9.9.100" nic="eth0"
ms ms_drbd_left p_drbd_left \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
ms ms_drbd_stacked p_drbd_stacked \
meta master-max="1" clone-max="1" \
clone-node-max="1" master-node-max="1" \
notify="true" target-role="Master"
colocation c_ip_on_left_master \
inf: p_ip_stacked_left ms_drbd_left:Master
colocation c_drbd_stacked_on_ip_left \
inf: ms_drbd_stacked p_ip_stacked_left
order o_ip_before_stacked_left \
inf: p_ip_stacked_left ms_drbd_stacked:start
order o_drbd_left_before_stacked_left \
inf: ms_drbd_left:promote ms_drbd_stacked:startこの構成を /tmp/crm.txt という一時ファイルに保存し、次のコマンドで現在のクラスタにインポートします。
crm configure < /tmp/crm.txt
CIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
‘alice’ と ‘bob’ をレプリケートするリソース ‘left’ を起動し、いずれかのノードをマスターに昇格します。
-
IPアドレス10.9.9.100 ( ‘alice’ または ‘bob’ 、いずれかのリソース ‘left’ のマスターロールを担っている方)を起動します。
-
IPアドレスを設定したのと同じノード上で、DRBDリソース
stackedが起動します。 -
target-role=”Master”が指定されているため、スタックしたDRBDリソースがプライマリになります。
さて、以下の設定を作り、クラスタ ‘right’ に進みましょう。
primitive p_drbd_right ocf:linbit:drbd \
params drbd_resource="right"
primitive p_drbd_stacked ocf:linbit:drbd \
params drbd_resource="stacked"
primitive p_ip_stacked_right ocf:heartbeat:IPaddr2 \
params ip="10.9.10.101" nic="eth0"
ms ms_drbd_right p_drbd_right \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
ms ms_drbd_stacked p_drbd_stacked \
meta master-max="1" clone-max="1" \
clone-node-max="1" master-node-max="1" \
notify="true" target-role="Slave"
colocation c_drbd_stacked_on_ip_right \
inf: ms_drbd_stacked p_ip_stacked_right
colocation c_ip_on_right_master \
inf: p_ip_stacked_right ms_drbd_right:Master
order o_ip_before_stacked_right \
inf: p_ip_stacked_right ms_drbd_stacked:start
order o_drbd_right_before_stacked_right \
inf: ms_drbd_right:promote ms_drbd_stacked:startCIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
‘charlie’ と ‘daisy’ 間をレプリケートするDRBDリソース ‘right’ を起動し、これらのノードのいずれかをマスターにします。
-
IPアドレス10.9.10.101を開始します( ‘charlie’ または ‘daisy’ のいずれか。リソース ‘right’ でマスターの役割を担っている方)。
-
IPアドレスを設定したのと同じノード上で、DRBDリソース
stackedが起動します。 -
target-role="Slave"が指定されているため、スタックリソースはセカンダリのままになります。
7.5. 2セットのSANベースPacemakerクラスタ間をDRBDでレプリケート
これは、拠点が離れた構成に用いるやや高度な設定です。2つのクラスタが関与しますが、それぞれのクラスタは別々のSAN(ストレージエリアネットワーク)ストレージにアクセスします。サイト間のIPネットワークを使って2つのSANストレージのデータを同期させるためにDRBDを使います。
次の図で概念を説明します。
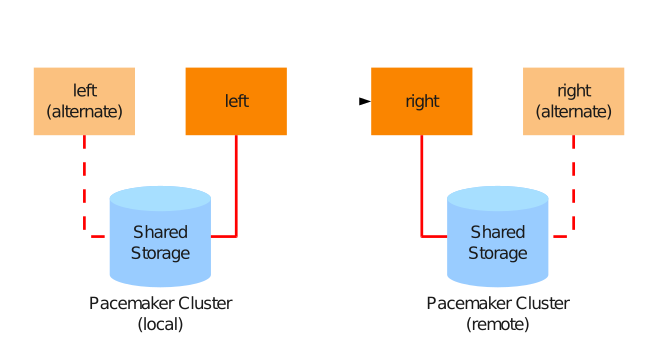
このような構成の場合、DRBDの通信にかかわるホストをあらかじめ明確に指定しておくことは不可能です。つまり、動的接続構成の場合、DRBDは特定の物理マシンではなく仮想IPアドレスで通信先を決めます。
| このタイプの設定は、通常、DRBD Proxyや、またはトラック輸送のレプリケーションと組み合わせます。 |
このタイプの設定は共有ストレージを扱うので、STONITHを構築してテストすることは、正常に動作するために必要不可欠です。ただし、STONITHは本書の範囲を超えるので、以下の設定例は省略しています。
7.5.1. DRBDリソース構成
動的接続するDRBDリソースを有効にするには、次のように drbd.conf を設定します。
resource <resource> {
...
device /dev/drbd0;
disk /dev/sda1;
meta-disk internal;
floating 10.9.9.100:7788;
floating 10.9.10.101:7788;
}floating のキーワードは、通常リソース設定の on <host>
セクションの代わりに指定します。このモードでは、DRBDはホスト名ではなく、IPアドレスやTCPポートで相互接続を認識します。動的接続を適切に運用するには、物理IPアドレスではなく仮想IPアドレスを指定してください(これはとても重要です)。上の例のように、離れた地点ではそれぞれ別々のIPネットワークに属するのが一般的です。したがって、動的接続を正しく運用するにはDRBDの設定だけではなく、ルータやファイアウォールの適切な設定も重要です。
7.5.2. Pacemakerリソース構成
DRBD動的接続の設定には、少なくともPacemaker設定が必要です(2つの各Pacemakerクラスタに係わる)。
-
仮想クラスタIPアドレス
-
マスター/スレーブDRBDリソース(DRBD OCFリソースエージェントを使用)
-
リソースを適切なノードで正しい順序に起動するための各種制約
レプリケーション用アドレスに 10.9.9.100 を使う動的接続構成と、 mysql というリソースを構築するには、次のように crm
コマンドでPacemakerを設定します。
crm configure
crm(live)configure# primitive p_ip_float_left ocf:heartbeat:IPaddr2 \
params ip=10.9.9.100
crm(live)configure# primitive p_drbd_mysql ocf:linbit:drbd \
params drbd_resource=mysql
crm(live)configure# ms ms_drbd_mysql drbd_mysql \
meta master-max="1" master-node-max="1" \
clone-max="1" clone-node-max="1" \
notify="true" target-role="Master"
crm(live)configure# order drbd_after_left \
inf: p_ip_float_left ms_drbd_mysql
crm(live)configure# colocation drbd_on_left \
inf: ms_drbd_mysql p_ip_float_left
crm(live)configure# commit
bye
CIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
IPアドレス10.9.9.100を起動する( ‘alice’ または ‘bob’ のいずれか)
-
IPアドレスの設定にもとづいてDRBDリソースを起動します。
-
DRBDリソースをプライマリにします。
次に、もう一方のクラスタで、これとマッチングする設定を作成します。そのPacemakerのインスタンスを次のコマンドで設定します。
crm configure
crm(live)configure# primitive p_ip_float_right ocf:heartbeat:IPaddr2 \
params ip=10.9.10.101
crm(live)configure# primitive drbd_mysql ocf:linbit:drbd \
params drbd_resource=mysql
crm(live)configure# ms ms_drbd_mysql drbd_mysql \
meta master-max="1" master-node-max="1" \
clone-max="1" clone-node-max="1" \
notify="true" target-role="Slave"
crm(live)configure# order drbd_after_right \
inf: p_ip_float_right ms_drbd_mysql
crm(live)configure# colocation drbd_on_right
inf: ms_drbd_mysql p_ip_float_right
crm(live)configure# commit
bye
CIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
IPアドレス10.9.10.101を起動する( ‘charlie’ または ‘daisy’ のいずれか)。
-
IPアドレスの設定にもとづいてDRBDリソースを起動します。
-
target-role="Slave"が指定されているため、DRBDリソースは、セカンダリのままになります。
7.5.3. サイトのフェイルオーバ
拠点が離れた構成では、サービス自体をある拠点から他の拠点に切り替える必要が生じるかもしれません。これは、計画された移行か、または悲惨な出来事の結果でしょう。計画にもとづく移行の場合、一般的な手順は次のようになります。
-
サービス移行元のクラスタに接続し、影響を受けるDRBDリソースの ‘target-role’ 属性を Master から Slave に変更します。DRBDがプライマリであることに依存したリソースは自動的に停止し、その後DRBDはセカンダリに降格します。DRBDはセカンダリのまま動作し続け、新しいプライマリからのデータ更新を受け取ってレプリケートします。
-
サービス移行先のクラスタに接続し、DRBDリソースの ‘target-role’ 属性を Slave から Master に変更します。DRBDリソースは昇格し、DRBDリソースのプライマリ側に依存した他のPacemakerリソースを起動します。そしてリモート拠点への同期が更新されます。
-
フェイルバックをするには、手順を逆にするだけです。
アクティブな拠点で壊滅的な災害が起きると、その拠点はオフラインになり、以降その拠点からバックアップ側にレプリケートできなくなる可能性があります。このような場合には
-
リモートサイトが機能しているならそのクラスタに接続し、DRBDリソースの ‘target-role’ 属性を Slave から Master に変えてください。DRBDリソースは昇格し、DRBDリソースがプライマリになることに依存する他のPacemakerリソースも起動します。DRBDリソースを昇格し、DRBDリソースのプライマリ側に依存した他のPacemakerリソースを起動します。そしてリモート拠点への同期が更新されます。
-
元の拠点が回復または再構成される、DRBDリソースに再度接続できるようになります。その後、逆の手順でフェイルバックします。
8. DRBDとRed Hat Cluster Suite
この章ではRDBDをRed Hat Cluster高可用性クラスタのためのレプリケーションストレージとして使用する方法を説明します。
| ここでは非公式な Red Hat Cluster という用語を歴代の複数の正式な製品名として使用しており、そのなかには Red Hat Cluster Suite と Red Hat Enterprise Linux High Availability Add-On が含まれています。 |
8.1. Red Hat Clusterの背景情報
8.1.1. Fencing
Red Hat
Clusterは本来は共有ストレージクラスタを主な対象として設計されたもので、ノードフェンシングによって共有リソースへの非協調的な同時アクセスを回避します。Red
Hat Cluster Suiteのフェンシングインフラストラクチャは、フェンシングデーモン fenced
とシェルスクリプトとして実装されるフェンシングエージェントに依存しています。
DRBDベースのクラスタは共有ストレージリソースを利用しないため、DRBDとしては厳密にはフェンシングは必要ありません。 ただし、Red Hat Cluster SuiteはDRBDベースの構成の場合でもフェンシングを必要とします。
8.1.2. リソースグループマネージャ
リソースグループマネージャ( rgmanager または clurgmgr
)はPacemakerと似ています。これは、クラスタ管理スイートと管理対象アプリケーションとの間の主要なインタフェースとして機能します。
Red Hat Clusterリソース
Red Hat Clusterでは、個々の高可用性アプリケーション、ファイルシステム、IPアドレスなどを resource と呼びます。
たとえば、NFSエクスポートがマウントされているファイルシステムに依存するように、リソースは互いに依存しています。リソースは別のリソース内に入れ子になって、リソースツリーを構成します。入れ子の内部のリソースが、入れ子の外部のリソースからパラメータを継承する場合もあります。Pacemakerにはリソースツリーの概念はありません。
Red Hat Clusterサービス
相互に依存するリソースの集合をサービスと呼びます。Pacemakerではこのような集合をリソースグループと呼んでいます。
rgmanagerリソースエージェント
rgmanager により呼び出されるリソースエージェントは、Pacemakerで使用されるものと同様に、Open Cluster
Framework
(OCF)で定義されたシェルベースのAPIを使用しますが、Pacemakerはフレームワークで定義されていない拡張機能も利用します。このように理論的には、Red
Hat Cluster
SuiteとPacemakerのリソースエージェントはおおむね互換性がありますが、実際にはこの2つのクラスタ管理スイートは似たようなタスクや同一のタスクに異なるリソースエージェントを使用します。
Red Hat Clusterリソースエージェントは /usr/share/cluster
ディレクトリにインストールされます。オールインワン型のPacemaker OCFリソースエージェントとは異なり、一部の Red Hat
Clusterリソースエージェントは、実際のシェルコードを含む .sh ファイルと、XML形式のリソースエージェントメタデータを含む、
.metadata ファイルに分割されています。
DRBDは Red Hat Clusterリソースエージェントも提供しています。これは通常通りのディレクトリに drbd.sh および
drbd.metadata としてインストールされています。
8.2. Red Hat Clusterの構成
ここでは、Red Hat Clusterを実行するために必要な構成手順の概要を説明します。クラスタ構成の準備は比較的容易で、すべてのDRBDベースのRed Hat Clusterに必要なのは、2つの参加ノード(Red Hatのドキュメントではクラスタメンバと呼ばれる)フェンシングデバイスだけです。
| Red Hat clusterの構成の詳細は、http://www.redhat.com/docs/manuals/csgfs/[Red Hat ClusterとGFS(Global File System)についてのRed Hatのマニュアルをご参照ください。] |
8.2.1. cluster.conf ファイル
RHELクラスタの構成は単一の設定ファイル
/etc/cluster/cluster.conf に記載されています。次のような方法でクラスタ構成を管理できます。
これがもっとも簡単な方法です。テキストエディタ以外に必要なものはありません。
system-config-cluster GUIを使用するこれはGladeを使用してPythonで記述されたGUIアプリケーションです。Xディスプレイ(直接サーバコンソール上、またはSSH経由のトンネル)が必要です。
Congaインフラストラクチャは、ローカルクラスタ管理システムと通信するノードエージェント( ricci
)、クラスタリソースマネージャ、クラスタLVMデーモン、および管理用Webアプリケーション( luci
)から構成されます。luciを使用して、シンプルなWebブラウザでクラスタインフラストラクチャを構成することができます。
8.3. Red Hat ClusterフェイルオーバクラスタでDRBDを使用する
| ここでは、GFSについては取り上げず、Red Hat Clusterフェイルオーバクラスタ用のDRBDの設定方法のみを取り上げます。GFS (およびGFS2)の構成については、DRBDとGFSの使用を参照してください。 |
このセクションでは、DRBDとPacemakerクラスタの同様のセクションのように、高可用性MySQLデータベースを構成することを前提としています。次のような構成パラメータを使用します。
-
データベースのストレージ領域として使用するDRBDリソース名は
mysqlで、これによりデバイス/dev/drbd0を管理する。 -
DRBDデバイスにext3ファイルシステムが格納され、これが
/var/lib/mysql(デフォルトのMySQLデータディレクトリ)にマウントされる。 -
MySQLデータベースがこのファイルシステムを利用し、専用クラスタIPアドレス192.168.42.1で待機する。
8.3.1. クラスタ構成の設定
高可用性MySQLデータベースを設定するには、 /etc/cluster/cluster.conf
ファイルを作成するか変更して、次の構成項目を記述します。
まず /etc/cluster/cluster.conf を適切なテキストエディタで開きリソース構成に次の項目を記述します。
<rm>
<resources />
<service autostart="1" name="mysql">
<drbd name="drbd-mysql" resource="mysql">
<fs device="/dev/drbd/by-res/mysql/0"
mountpoint="/var/lib/mysql"
fstype="ext3"
name="mysql"
options="noatime"/>
</drbd>
<ip address="10.9.9.180" monitor_link="1"/>
<mysql config_file="/etc/my.cnf"
listen_address="10.9.9.180"
name="mysqld"/>
</service>
</rm>| この例では、ボリュームリソースが1つであることを前提にしています。 |
<service/> でリソース参照を相互に入れ子にするのは、Red Hat Cluster Suiteでリソースの依存関係を記述する方法です。
構成が完了したら、必ず、 <cluster> 要素の config_version
属性をインクリメントしてください。次のコマンドを実行して、実行中のクラスタ構成に変更内容をコミットします。
ccs_tool update /etc/cluster/cluster.conf cman_tool version -r <version>
必ず、2番目のコマンドの <version> を新しいクラスタ構成のバージョン番号と置き換えてください。
cluster.conf ファイルに drbd リソースエージェントを含めると、 system-config-cluster
GUI構成ユーティリティとConga
Webベースクラスタ管理インフラストラクチャの両方が、クラスタ構成に関する問題についてのメッセージを返します。これは、2つのアプリケーションが提供するPythonクラスタ管理ラッパが、クラスタインフラストラクチャに他社製の拡張機能が使用されることを前提としていないためです。
|
したがって、クラスタ構成に drbd リソースエージェントを使用する場合は、クラスタ構成のために system-config-cluster
またはCongaを使用することはお勧めできません。これらのツールは正しく機能するはずですが、これらはクラスタの状態を監視するためにのみ使用してください。
9. DRBDとLVMの使用
この章では、DRBDの管理とLVM2について説明します。特に、次のような項目を取り上げます。
-
LVM論理ボリュームをDRBDの下位デバイスとして使用する。
-
DRBDデバイスをLVMの論理ボリュームとして使用する。
-
上記の2つを組み合わせ、DRBDを使用して階層構造のLVMを実装する。
上述の用語についてよく知らない場合は、LVMの基礎を参照してくださいまた、ここで説明する内容にとどまらず、LVMについてさらに詳しく理解することをお勧めします。
9.1. LVMの基礎
LVM2は、Linuxデバイスマッパフレームワークのコンテキストにおける論理ボリューム管理の実装です。元のLVM実装とは名前と略語を除き、実際には何の共通点もありません。古い実装(現在ではLVM1と呼ばれる)は時代遅れとみなされているため、ここでは取り上げません。
LVMを使用する際には、次に示す基本的なコンセプトを理解することが重要です。
PV (Physical Volume: 物理ボリューム)はLVMによってのみ管理される配下のブロックデバイスです。ハードディスク全体または個々のパーティションがPVになります。ハードディスクにパーティションを1つだけ作成して、これを独占的にLinux LVMで使用するのが一般的です。
パーティションタイプ”Linux LVM” (シグネチャは 0x8E
)を使用して、LVMが独占的に使用するパーティションを識別できます。ただし、これは必須ではありません。PVの初期化時にデバイスに書き込まれるシグネチャによってLVMがPVを認識します。
|
VG (Volume Group: ボリュームグループ)はLVMの基本的な管理単位です。VGは1つまたは複数のPVで構成されます。各VGは一意の名前を持ちます。実行時にPVを追加したり、PVを拡張して、VGを大きくすることができます。
実行時にVG内にLV (Logical Volume: 論理ボリューム)を作成することにより、カーネルの他の部分がこれらを通常のブロックデバイスとして使用できます。このように、LVはファイルシステムの格納をはじめ、ブロックデバイスと同様のさまざまな用途に使用できます。オンライン時にLVのサイズを変更したり、1つのPVから別のPVに移動したりすることができます(PVが同じVGに含まれる場合)。
スナップショットはLVの一時的なポイントインタイムコピーです。元のLV(コピー元ボリューム)のサイズが数百GBの場合でも、スナップショットは一瞬で作成できます。通常、スナップショットは元のLVと比べてかなり小さい領域しか必要としません。
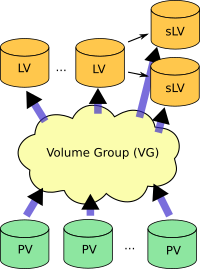
9.2. DRBDの下位デバイスとして論理ボリュームを使用する
Linuxでは、既存の論理ボリュームは単なるブロックデバイスであるため、これをDRBDの下位デバイスとして使用できます。この方法でLVを使用する場合は、通常通りにLVを作成してDRBD用に初期化するだけです。
次の例では、LVM対応システムの両方のノードに foo
というボリュームグループがすでに存在します。このボリュームグループの論理ボリュームを使用して、 r0 というDRBDリソースを作成します。
まず、次のコマンドで論理ボリュームを作成します。
lvcreate --name bar --size 10G foo Logical volume "bar" created
このコマンドはDRBDクラスタの両方のノードで実行する必要があります。これで、いずれかのノードに /dev/foo/bar
というブロックデバイスが作成されます。
次に、新しく作成したボリュームをリソース構成に加えます。
resource r0 {
...
on alice {
device /dev/drbd0;
disk /dev/foo/bar;
...
}
on bob {
device /dev/drbd0;
disk /dev/foo/bar;
...
}
}これでリソースを起動できます。手順はLVM対応以外のブロックデバイスと同様です。
9.3. DRBD同期中の自動LVMスナップショットの使用
DRBDが同期をしている間、 SyncTarget の状態は同期が完了するまでは Inconsistent (不整合)の状態です。この状況では SyncSource で(修復できない)障害があった場合に残念なことになります。正常なデータを持つノードが死に、誤った情報を持つノードが残ってしまいます。
LVM論理ボリュームをDRBDに渡す際には、同期の開始時に自動スナップショットを作成し、またこれを完了後に自動削除する方法によって、この問題を軽減することができます
再同期中に自動でスナップショットをするには、リソース設定に以下の行を追加します。
resource r0 {
handlers {
before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh";
after-resync-target "/usr/lib/drbd/unsnapshot-resync-target-lvm.sh";
}
}
2つのスクリプトはDRBDが呼び出したハンドラに自動で渡す $DRBD_RESOURCE$ 環境変数を解析します。
snapshot-resync-target-lvm.sh
スクリプトは、同期の開始前に、リソースが含んでいるすべてのボリュームのLVMスナップショットを作成します。そのスクリプトが失敗した場合、同期は開始されません。
同期が完了すると、 unsnapshot-resync-target-lvm.sh
スクリプトが必要のなくなったスナップショットを削除します。スナップショットの削除に失敗した場合、スナップショットは残り続けます。
| できる限り不要なスナップショットは確認するようにしてください。スナップショットが満杯だと、スナップショット自身と元のボリュームの障害の原因になります。 |
SyncSource に修復できない障害が起きて、最新のスナップショットに復帰したいときには、いつでも lvconvert -M
コマンドで行えます。
9.4. DRBDリソースを物理ボリュームとして構成する
DRBDリソースを物理ボリュームとして使用するためには、DRBDデバイスにPVのシグネチャを作成する必要があります。リソースが現在プライマリロールになっているノードで、 次のいずれかのコマンドを実行します。
# pvcreate /dev/drbdX
または
# pvcreate /dev/drbd/by-res/<resource>/0
| この例では、ボリュームリソースが1つであることを前提にしています。 |
次に、LVMがPVシグネチャをスキャンするデバイスのリストにこのデバイスを加えます。このためには、通常は
/etc/lvm/lvm.conf という名前のLVM設定ファイルを編集する必要があります。 devices セクションで filter
というキーワードを含む行を見つけて編集します。すべてののPVをDRBDデバイスに格納する場合には、次ように filter
オプションを編集します。
filter = [ "a|drbd.*|", "r|.*|" ]このフィルタ表現がDRBDデバイスで見つかったPVシグネチャを受け入れ、それ以外のすべてを拒否(無視)します。
デフォルトではLVMは /dev にあるすべてのブロックデバイスのPVシグネチャをスキャンします。これは filter=["a|.*|"]
に相当します。
|
LVMのPVでスタックリソースを使用する場合は、より明示的にフィルタ構成を指定する必要があります。対応する下位レベルリソースや下位デバイスでPVシグネチャを無視している場合、LVMはスタックリソースでPVシグネチャを検出する必要があります。次の例では、下位レベルDRBDリソースは0から9のデバイスを使用し、スタックリソースは10以上のデバイスを使用しています。
filter = [ "a|drbd1[0-9]|", "r|.*|" ]このフィルタ表現は、 /dev/drbd10 から /dev/drbd19
までのDRBDのデバイスで見つかったPVシグニチャを受け入れ、それ以外のすべてを拒否(無視)します。
lvm.conf ファイルを変更したら vgscan
コマンドを実行します。LVMは構成キャッシュを破棄し、デバイスを再スキャンしてPVシグネチャを見つけます。
システム構成に合わせて、別の filter 構成を使用することもできます。重要なのは、次の2つです。
-
PVとして使用するデバイスに、DRBDのデバイスを許容する
-
対応する下位レベルデバイスを拒否(除外)して、LVMが重複したPVシグネチャを見つけることを回避する。
さらに、次の設定で、LVMのキャッシュを無効にする必要があります。
write_cache_state = 0LVMのキャッシュを無効にした後、 /etc/lvm/cache/.cache を削除して、古いキャッシュを削除してください。
対向ノードでも、上記の手順を繰り返します。
システムのルートファイルシステムがLVM上にある場合、bootの際にボリュームグループはイニシャルRAMディスク(initrd)から起動します。そのため、LVMツールはinitrdイメージに含まれる
lvm.conf ファイルを検査します。そのため、 lvm.conf に変更を加えたら、ディストリビューションに応じてユーティリティ(
mkinitrd 、 update-initramfs など)で確実にアップデートしなければなりません。
|
新しいPVを構成したら、ボリュームグループに追加するか、 新しいボリュームグループを作成します。このとき、DRBDリソースがプライマリロールになっている必要があります。
# vgcreate <name> /dev/drbdX
| 同じボリュームグループ内にDRBD物理ボリュームとDRBD以外の物理ボリュームを混在させることができますが、これはお勧めできません。また、混在させても実際には意味がないでしょう。 |
VGを作成したら、 lvcreate
コマンドを使用して、(DRBD以外を使用するボリュームグループと同様に)ここから論理ボリュームを作成します。
9.5. 新しいDRBDボリュームを既存のボリュームグループへ追加する
新しいDRBDでバックアップした物理ボリュームを、ボリュームグループへ追加したいといった事があるでしょう。その場合には、新しいボリュームは既存のリソース設定に追加しなければなりません。そうすることでVG内の全PVのレプリケーションストリームと書き込みの適合度が確保されます。
| LVMボリュームグループをPacemakerによる高可用性LVMで説明しているようにPacemakerで管理している場合には、DRBD設定の変更前にクラスタメンテナンスモードになっている事が必須です。 |
追加ボリュームを加えるには、リソース設定を次のように拡張します。
resource r0 {
volume 0 {
device /dev/drbd1;
disk /dev/sda7;
meta-disk internal;
}
volume 1 {
device /dev/drbd2;
disk /dev/sda8;
meta-disk internal;
}
on alice {
address 10.1.1.31:7789;
}
on bob {
address 10.1.1.32:7789;
}
}
DRBD設定が全ノード間で同じである事を確認し、次のコマンドを発行します。
# drbdadm adjust r0
これによって、リソース r0 の新規ボリューム 1 を有効にするため、暗黙的に drbdsetup new-minor r0 1
が呼び出されます。新規ボリュームがレプリケーションストリームに追加されると、イニシャライズやボリュームグループへの追加ができるようになります。
# pvcreate /dev/drbd/by-res/<resource>/1 # vgextend <name> /dev/drbd/by-res/<resource>/1
で新規PVの /dev/drbd/by-res/<resource>/1 が <name>
VGへ追加され、VG全体にわたって書き込みの忠実性を保護します。
9.6. DRBDを使用する入れ子のLVM構成
論理ボリュームをDRBDの下位デバイスとして使用し、かつ、同時にDRBDデバイス自体を物理ボリュームとして使用することもできます。例として、次のような構成を考えてみましょう。
-
/dev/sda1と/dev/sdb1という2つのパーティションがあり、これらを物理ボリュームとして使用します。 -
2つのPVが
localというボリュームグループに含まれます。 -
このGVに10GiBの論理ボリュームを作成し、
r0という名前を付けます。 -
このLVがDRBDリソースのローカル下位デバイスになります。名前は同じ
r0で、デバイス/dev/drbd0に対応します。 -
このデバイスが
replicatedというもう1つのボリュームグループの唯一のPVになります。 -
このVGには
foo(4GiB)とbar(6GiB)というさらに2つの論理ボリュームが含まれます。
この構成を有効にするために、次の手順を行います。
-
/etc/lvm/lvm.confで適切なfilterオプションを設定します:filter = ["a|sd.*|", "a|drbd.*|", "r|.*|"]このフィルタ表現が、SCSIおよびDRBDデバイスで見つかったPVシグネチャを受け入れ、その他すべてを拒否(無視)します。
lvm.confファイルを変更したらvgscanコマンドを実行します。LVMは構成キャッシュを破棄し、デバイスを再スキャンしてPVシグネチャを見つけます。 -
LVMキャッシュ無効の設定:
write_cache_state = 0LVMのキャッシュを無効にした後、
/etc/lvm/cache/.cacheを削除して、古いキャッシュを削除してください。 -
ここで、2つのSCSIパーティションをPVとして初期化します。
# pvcreate /dev/sda1 Physical volume "/dev/sda1" successfully created # pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created
-
次に、初期化した2つのPVを含む
localという名前の下位レベルVGを作成します。# vgcreate local /dev/sda1 /dev/sda2 Volume group "local" successfully created
-
これで、DRBDの下位デバイスとして使用する論理ボリュームを作成できます。
# lvcreate --name r0 --size 10G local Logical volume "r0" created
-
対向ノードに対して、ここまでのすべての手順を繰り返します。
-
/etc/drbd.confを編集して、r0という名前の新しいリソースを作成します:resource r0 { device /dev/drbd0; disk /dev/local/r0; meta-disk internal; on <host> { address <address>:<port>; } on <host> { address <address>:<port>; } }新しいリソース構成を作成したら、忘れずに
drbd.confの内容を対向ノードにコピーします。 -
リソースを初めて有効にするに従って(両方のノードの)リソースを初期化します。
-
一方のノードリソースを昇格します。
# drbdadm primary r0
-
リソースを昇格したノードで、DRBDデバイスを新しい物理ボリュームとして初期化します:
# pvcreate /dev/drbd0 Physical volume "/dev/drbd0" successfully created
-
初期化したPVを使用して、同じノードに
replicatedというVGを作成します。# vgcreate replicated /dev/drbd0 Volume group "replicated" successfully created
-
最後に、新しく作成したこのVG内に新しい論理ボリュームを作成します。
VG:
# lvcreate --name foo --size 4G replicated Logical volume "foo" created # lvcreate --name bar --size 6G replicated Logical volume "bar" created
これで、論理ボリューム foo と bar をローカルノードで /dev/replicated/foo と
/dev/replicated/bar として使用できます。
9.6.1. VG を他のノードにスイッチ
他のノードでも使用できるように、プライマリノードで次のコマンドを実行します。
# vgchange -a n replicated 0 logical volume(s) in volume group "replicated" now active # drbdadm secondary r0
次に他のノード(まだセカンダリの)でコマンドを発行します。
# drbdadm primary r0 # vgchange -a y replicated 2 logical volume(s) in volume group "replicated" now active
これでブロックデバイス /dev/replicated/foo と /dev/replicated/bar
が他の(現在はプライマリの)ノードで有効になります。
9.7. Pacemakerによる高可用性LVM
対向ノード間でのボリュームグループの転送と、対応する有効な論理ボリュームの作成のプロセスは自動化することができます。Pacemakerの LVM
リソースエージェントはまさにこのために作られています。
既存のPacemaker管理下にあるDRBDの下位デバイスのボリュームグループをレプリケートするために、 crm
シェルで次のコマンドを実行してみましょう。
primitive p_drbd_r0 ocf:linbit:drbd \
params drbd_resource="r0" \
op monitor interval="29s" role="Master" \
op monitor interval="31s" role="Slave"
ms ms_drbd_r0 p_drbd_r0 \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
primitive p_lvm_r0 ocf:heartbeat:LVM \
params volgrpname="r0"
colocation c_lvm_on_drbd inf: p_lvm_r0 ms_drbd_r0:Master
order o_drbd_before_lvm inf: ms_drbd_r0:promote p_lvm_r0:start
commit
この設定を反映させると、現在のDRBDリソースのプライマリ(マスター)ロールがどちらであっても、Pacemakerは自動的に r0
ボリュームグループを有効にします。
10. DRBDとGFSの使用
この章では、DRBDリソースを共有GFS (Global File System)バージョン2を持つブロックデバイスとして設定する方法をかいつまんで説明します。
詳細な手順についてはLINBITの技術ガイドをご参照ください。http://linbit.com/en/downloads/tech-guides[GFS in dual-primary setups].
|
このガイドではDRBDのデュアルプライマリセットアップを扱います。デュアルプライマリセットアップは適切な設定を行わないと
データが破壊される可能性があります。 デュアルプライマリリソースの設定を行う予定のある場合、事前にLINBITの技術ガイドをお読みくださいhttp://linbit.com/en/downloads/tech-guides?download=15:dual-primary-think-twice[“Dual
primary: think twice”] もしこのドキュメントに何か不明点や不明瞭な点があれば、お気軽にLINBITへご相談ください。 |
10.1. GFSの基礎
Red Hat Global File System (GFS)は、同時アクセス共有ストレージファイルシステムのRed Hatによる実装です。同様のファイルシステムのように、GFSでも複数のノードが読み取り/書き込みモードで、同時に同じストレージデバイスにアクセスすることが可能です。データが破損するおそれはありません。これには、クラスタメンバからの同時アクセスを管理する DLM (Distributed Lock Manager)が使用されます。
本来、GFSは従来型の共有ストレージデバイスを管理するために設計されたものですが、デュアルプライマリモードでDRBDをGFS用のレプリケートされたストレージデバイスとして問題なく使用することができます。アプリケーションについては、読み書きの待ち時間が短縮されるというメリットがあります。 これは、GFSが一般的に実行されるSANデバイスとは異なり、DRBDが通常はローカルストレージに対して読み書きを行うためです。また、DRBDは各GFSファイルシステムに物理コピーを追加して、冗長性を確保します。
GFSファイルシステムは通常はRedHat独自のクラスタ管理フレームワークのRed Hat Clusterと密接に統合されています。この章ではDRBDをGFSとともに使用する方法を Red Hat Clusterの観点から説明します。また、Pacemakerクラスタマネージャへの接続の説明では、リソースマネジメントとSTONITHについても説明します。
GFS、Pacemaker、Red Hat ClusterはRed Hat Enterprise Linux (RHEL)と、CentOSなどの派生ディストリビューションで入手できます。同じソースからビルドされたパッケージがDebian GNU/Linuxでも入手できます。この章の説明は、Red Hat Enterprise LinuxシステムでGFSを実行することを前提にしています。
10.2. GFS2 用の DRBDリソースの作成
GFSは共有クラスタファイルシステムで、すべてのクラスタノードからストレージに対して同時に読み取り/書き込みアクセスが行われることを前提としています。したがって、GFSファイルシステムを格納するために使用するDRBDリソースはデュアルプライマリモードで設定する必要があります。また、スプリットブレインから自動的に回復するためのDRBDの機能を使用することをお勧めします。両ノードのリソース昇格やGFSファイルシステムの開始は、Pacemakerが制御します。DRBDリソースの準備をするため、リソース構成に次の行を追加してください。
resource <resource> {
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
...
}
...
}|
回復ポリシーを設定することは、事実上、自動データロス設定を行うことです。十分にご理解のうえご使用ください。 |
これらのオプションを新しく構成したリソースに追加したら、通常どおりにリソースを初期化できます。リソースの
allow-two-primaries オプションが yes
に設定されているので、両ノードのリソースをプライマリに昇格することができます。
|
再度確認してください fencing/STONITHを構成している事を確認し、すべてのユースケースを広範にカバーするよう、特にデュアルプライマリの設定をテストしてください。 |
10.2.1. デュアルプライマリリソースのリソースフェンシングを有効にする
DRBDのリソースフェンシングを有効にするためには、DRBD構成中に以下のセクションが必要です。
disk {
fencing resource-and-stonith;
}
handlers {
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
after-resync-target "/usr/lib/drbd/crm-unfence-peer.sh";
}このスクリプトは、DRBDのインストール時に追加されます。
|
クラスタのデュアルプライマリ設定でのフェンシングでは、DRBDユーザーズガイドの「DRBDとRed Hat Cluster Suite」セクションの短さに惑わされないでください。すべてのデュアルプライマリでクラスタのフェンシング設定が必要です。詳細な情報については、Red Hat Clusterのドキュメントをご参照ください。http://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux/6/html/Cluster_Administration/s1-config-fence-devices-ccs-CA.html[5.5.Configuring Fence Devices]また、http://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux/6/html/Cluster_Administration/s1-config-member-ccs-CA.html[5.6.Configuring Fencing for Cluster Members] |
10.3. CMANを構成する
GFSを動作させるには、Red Hatクラスタマネージャの cman が必要です。 cman は、次のステップで行う pacemaker
のように柔軟で構成しやすくありません。
|
もし |
GFSファイルシステムを作成する前に cman を構成します。
|
2ノードクラスタを構成する場合、クォーラムを獲得することはできません。cmanにクォーラムを無視する設定を行う事が必要です。以下のようにして設定できます。 # sed -i.orig "s/.*CMAN_QUORUM_TIMEOUT=.*/CMAN_QUORUM_TIMEOUT=0/g" /etc/sysconfig/cman |
次のものは、 /etc/cluster/cluster.conf での cman のクラスタ構成です。
<?xml version="1.0"?>
<cluster name="my-cluster" config_version="1">
<logging debug="off"/>
<clusternodes>
<clusternode name="gfs-machine1" nodeid="1">
<fence>
<method name="pcmk-redirect">
<device name="pcmk" port="gfs-machine1"/>
</method>
</fence>
</clusternode>
<clusternode name="gfs-machine2" nodeid="2">
<fence>
<method name="pcmk-redirect">
<device name="pcmk" port="gfs-machine2"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice name="pcmk" agent="fence_pcmk"/>
</fencedevices>
</cluster>これは、 cman にクラスタ名は my-cluster 、クラスタノード名は gfs-machine1 と gfs-machine2
であり、 pacemaker によってfencingされるという設定です。
構成が済んだら cman を起動します。
10.4. GFSファイルシステムの作成
デュアルプライマリのDRBDリソースでGFSファイルシステムを作成するには,次のコマンドを*1つ*(!)のノード(これは Primary でなければいけません)で実行します。
mkfs -t gfs2 -p lock_dlm -j 2 -t <cluster>:<name> /dev/<drbd-resource>
-j
オプションはGFS用に確保するジャーナルの数を示しています。これはGFSクラスタのノードの数と等しい値です。DRBDは2つまでのノードしかサポートしないため、ここで設定する値は常に2です。
|
DRBD 9では1つのディスクを2ノード以上で共有することができます。そうしたい場合には、大きなジャーナルの値を指定するか、稼動しているファイルシステムにジャーナルを作成する必要があります。 |
-t オプションはロックテーブル名を定義します。 <cluster>:<name> という形式が続きます。 <cluster> は
/etc/cluster/cluster.conf
に定義したクラスタ名に一致しなければなりません。このように、特定のクラスタのメンバだけにファイルシステムの使用が許可されます。これに対して、
<name> はクラスタ内で一意の任意のファイルシステム名です。
10.5. PacemakerでのGFS2ファイルシステムの使用
Pacemakerをクラスタリソースマネージャとして使用したい場合、現在の構成をPacemaerに設定して、リソースを管理するように設定しなければなりません。
|
Pacemakerの構成がfencingとSTONITHの動作のすべてに注意して行われていることを確認してください(詳細な情報についてはLINBIT社の技術ガイドをご参照ください。https://linbit.com/en/resources/technical-publications/[GFS in dual-primary setups] |
Pacemakerの構成は右記に記載のように行ってください。8.2.クラスタ構成にDRBDのサービスを追加する.
ここではデュアルプライマリ構成であるため、マスタースレーブ構成に次の変更を行います。
crm(live)configure# ms ms_drbd_xyz drbd_xyz \
meta master-max="2" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
master-max が 2 になっている点に注目ください。この設定によってDRBDリーソースが両クラスタノードで昇格されます。
さらに、GFSファイルシステムを両ノードで開始したいので、プリミティブのファイルシステムのクローンを追加します。
crm(live)configure# clone cl_fs_xyz p_fs_xyz meta interleave="true"
11. DRBDとOCFS2の使用
この章では、共有Oracle Cluster File Systemバージョン2 (OCFS2)を格納するブロックデバイスとしてDRBDリソースを設定する方法を説明します。
|
全てのクラスタファイルシステムには、fencingが必要です。DRBDリソース経由だけでなく、STONITHでもです。問題のあるメンバは必ずkillされなければなりません。 次のような設定がよいでしょう。 disk {
fencing resource-and-stonith;
}
handlers {
# Make sure the other node is confirmed
# dead after this!
fence-peer "/sbin/kill-other-node.sh";
}
これらは非揮発性のキャッシュである必要があります。GFS2に関するものであり、OCFS2についてではありませんが、 https://fedorahosted.org/cluster/wiki/DRBD_Cookbook が参考になるでしょう。 |
11.1. OCFS2の基礎
Oracle Cluster File Systemバージョン2 (OCFS2)は、Oracle Corporationが開発した同時アクセス共有ストレージファイルシステムです。前バージョンのOCFSはOracleデータベースペイロード専用に設計されていましたが、OCFS2はほとんどのPOSIXセマンティクスを実装する汎用ファイルシステムです。OCFS2の最も一般的なユースケースは、もちろんOracle Real Application Cluster (RAC)ですが、OCFS2は負荷分散NFSクラスタなどでも使用できます。
本来、CFS2は従来の共有ストレージデバイス用に設計されたものですが、デュアルプライマリDRBDにも問題なく配備できます。OCFS2が通常実行されるSANデバイスとは異なり、DRBDはローカルストレージに対して読み書きを行うため、ファイルシステムからデータを読み取るアプリケーションの読み取り待ち時間が短縮できるというメリットがあります。さらに、DRBDの場合は、単一のファイルシステムイメージを単に共有するのではなく、各ファイルシステムイメージにさらにコピーを追加するため、OCFS2に冗長性が加わります。
他の共有クラスタファイルシステムGFSなどと同様に、OCFS2で複数のノードが読み取り/書き込みモードで同じストレージデバイスに同時にアクセスできます。データが破損するおそれはありません。これには、クラスタノードからの同時アクセスを管理するDLM
(Distributed Lock
Manager)が使用されます。DLM自体は、システムに存在する実際のOCFS2ファイルシステムとは別個の仮想ファイルシステム(
ocfs2_dlmfs )を使用します。
OCFS2は組み込みクラスタ通信層を使用して、クラスタメンバシップおよびファイルシステムのマウントとマウント解除操作を管理したり、これらのタスクをPacemakerクラスタインフラストラクチャに委ねることができます。
OCFS2は、SUSE Linux Enterprise Server (OCFS2が主にサポートされる共有クラスタファイルシステム)、CentOS、Debian GNU/LinuxおよびUbuntu Server Editionで入手できます。また、OracleはRed Hat Enterprise Linux (RHEL)用のパッケージも提供しています。この章の説明は、SUSE Linux Enterprise ServerシステムでOCFS2を実行することを前提としています。
11.2. OCFS2用のDRBDリソースの作成
OCFS2は共有クラスタファイルシステムで、すべてのクラスタノードからストレージに対して同時に読み取り/書き込みアクセスが行われることを前提としています。したがって、OCFS2ファイルシステムを格納するために使用するDRBDリソースは、デュアル・プライマリモードで設定する必要があります。また、スプリットブレインから自動的に回復するためのDRBDの機能を使用することをお勧めします。リソースは起動後直ちにプライマリロールに切り替わる必要があります。上記のすべてを実行するために、次の行をリソース構成に記述してください。
resource <resource> {
startup {
become-primary-on both;
...
}
net {
# allow-two-primaries yes;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
...
}
...
}|
自動回復ポリシーを設定することは、事実上、自動データロス設定を行うことです。十分にご理解のうえご使用ください。 |
最初の構成の際に allow-two-primaries
オプションを有効にするのはお勧めできません。これは、最初のリソース同期が完了してから有効にしてください。
これらのオプションを新しく構成したリソースに追加したら、通常どおりにリソースを初期化できます。リソースの
allow-two-primaries オプションを yes
にすると、両方のノードのリソースをプライマリロールに昇格させることができます。
11.3. OCFS2ファイルシステムの作成
OCFS対応の mkfs コマンドを使って、OCFS2ファイルシステムを作成します。
mkfs -t ocfs2 -N 2 -L ocfs2_drbd0 /dev/drbd0 mkfs.ocfs2 1.4.0 Filesystem label=ocfs2_drbd0 Block size=1024 (bits=10) Cluster size=4096 (bits=12) Volume size=205586432 (50192 clusters) (200768 blocks) 7 cluster groups (tail covers 4112 clusters, rest cover 7680 clusters) Journal size=4194304 Initial number of node slots: 2 Creating bitmaps: done Initializing superblock: done Writing system files: done Writing superblock: done Writing backup superblock: 0 block(s) Formatting Journals: done Writing lost+found: done mkfs.ocfs2 successful
2ノードスロットOCFS2ファイルシステムが /dev/drbd0 に作成され、ファイルシステムのラベルが ocfs2_drbd0
に設定されます。 mkfs の呼び出し時に、その他のオプションを指定することもできます。詳細は mkfs.ocfs2
システムマニュアルページを参照ください。
11.4. PacemakerによるOCFS2の管理
11.4.1. PacemakerにデュアルプライマリDRBDリソースを追加する
既存のデュアルプライマリDRBDリソースは、次の crm
設定でPacemakerリソース管理に追加することができます。
primitive p_drbd_ocfs2 ocf:linbit:drbd \
params drbd_resource="ocfs2"
ms ms_drbd_ocfs2 p_drbd_ocfs2 \
meta master-max=2 clone-max=2 notify=true
メタ変数 master-max=2
に注意してください。これはPacemakerのマスター/スレーブのデュアルマスターモードを有効にします。これはまた、
allow-two-primaries も yes
にDRBD設定で設定されている必要があります。これらを忘れると、リソースの検証中にPacemakerでフラグ設定エラーが発生するかもしれません。
|
11.4.2. OCFS2をPacemakerで管理するには
OCFS2とロックマネージャ(DLM)の分散カーネルを管理するために、Pacemakerは、3つの異なるリソースエージェントを使用します。
-
ocf:pacemaker:controld— PacemakerのDLMに対してのインタフェース -
ocf:ocfs2:o2cb— PacemakerのOCFS2クラスタ管理へのインタフェース -
ocf:heartbeat:Filesystem— Pacemakerのクローンとして構成したときにクラスタファイルシステムをサポートする汎用ファイルシステム管理リソースエージェント
次の crm
設定のようにリソースグループのクローンを作成することによって、OCFS2の管理に必要なPacemakerリソースをすべてのノードで起動できます。
primitive p_controld ocf:pacemaker:controld
primitive p_o2cb ocf:ocfs2:o2cb
group g_ocfs2mgmt p_controld p_o2cb
clone cl_ocfs2mgmt g_ocfs2mgmt meta interleave=trueこの構成がコミットされると、Pacemakerは、クラスタ内のすべてのノードで controld と o2cb
のリソースタイプのインスタンスを起動します。
11.4.3. PacemakerにOCFS2ファイルシステムを追加する
PacemakerはOCF2ファイルシステムにアクセスするのに、従来の ocf:heartbeat:Filesystem
リソースエージェントを使います。これはクローンモードにおいてもです。Pacemakerの管理下にOCFS2ファイルシステムを配置するには、次の
crm 設定を使用します。
primitive p_fs_ocfs2 ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/ocfs2/0" directory="/srv/ocfs2" \
fstype="ocfs2" options="rw,noatime"
clone cl_fs_ocfs2 p_fs_ocfs2| この例では、ボリュームリソースが1つであることを前提にしています。 |
11.4.4. OCFS2ファイルシステムを管理するPacemakerの制約の追加
すべてのOCFS2関連のリソースとクローンを結びつけるには、Pacemaker構成に以下の制約を加えてください。
order o_ocfs2 inf: ms_drbd_ocfs2:promote cl_ocfs2mgmt:start cl_fs_ocfs2:start
colocation c_ocfs2 inf: cl_fs_ocfs2 cl_ocfs2mgmt ms_drbd_ocfs2:Master11.5. Pacemakerを使わないOCFS2管理
| OCFS2 DLMをサポートしない旧バージョンのPacemakerしか使えない場合、この節が参考になります。したがって、この節は以前の方式を使っている方の参照のためにだけ残してあります。新規インストールの場合は、Pacemaker方式を使ってください。 |
11.5.1. OCFS2をサポートするようにクラスタを設定する
設定ファイルの作成
OCFS2は主要な設定ファイル /etc/ocfs2/cluster.conf を使用します。
OCFS2クラスタを作成する際には、必ず、両方のホストを設定ファイルに追加してください。クラスタの相互接続通信には、通常はデフォルトポート(7777)が適切です。他のポート番号を選択する場合は、DRBD (および他の構成されたTCP/IP)が使用する既存のポートと衝突しないポートを選択する必要があります。
cluster.conf ファイルを直接編集したくない場合は、 ocfs2console
というグラフィカルな構成ユーティリティを使用することもできます。通常はこちらのほうが便利です。いずれの場合も
/etc/ocfs2/cluster.conf ファイルの内容はおおよそ次のようになります。
node:
ip_port = 7777
ip_address = 10.1.1.31
number = 0
name = alice
cluster = ocfs2
node:
ip_port = 7777
ip_address = 10.1.1.32
number = 1
name = bob
cluster = ocfs2
cluster:
node_count = 2
name = ocfs2クラスタ構成を設定したら、 scp を使用して構成をクラスタの両方のノードに配布します。
O2CBドライバの設定
SUSE Linux Enterpriseシステム
SLESでは、 o2cb の起動スクリプトの configure オプションを利用することができます。
/etc/init.d/o2cb configure
Configuring the O2CB driver.
This will configure the on-boot properties of the O2CB driver.
The following questions will determine whether the driver is loaded on
boot. The current values will be shown in brackets ('[]'). Hitting
<ENTER> without typing an answer will keep that current value. Ctrl-C
will abort.
Load O2CB driver on boot (y/n) [y]:
Cluster to start on boot (Enter "none" to clear) [ocfs2]:
Specify heartbeat dead threshold (>=7) [31]:
Specify network idle timeout in ms (>=5000) [30000]:
Specify network keepalive delay in ms (>=1000) [2000]:
Specify network reconnect delay in ms (>=2000) [2000]:
Use user-space driven heartbeat? (y/n) [n]:
Writing O2CB configuration: OK
Loading module "configfs": OK
Mounting configfs filesystem at /sys/kernel/config: OK
Loading module "ocfs2_nodemanager": OK
Loading module "ocfs2_dlm": OK
Loading module "ocfs2_dlmfs": OK
Mounting ocfs2_dlmfs filesystem at /dlm: OK
Starting O2CB cluster ocfs2: OK
.Debian GNU/Linux システム
Debianの場合は、 /etc/init.d/o2cb の configure オプションは使用できません。代わりに、
ocfs2-tools パッケージを再設定してドライバを有効にします。
dpkg-reconfigure -p medium -f readline ocfs2-tools Configuring ocfs2-tools Would you like to start an OCFS2 cluster (O2CB) at boot time? yes Name of the cluster to start at boot time: ocfs2 The O2CB heartbeat threshold sets up the maximum time in seconds that a node awaits for an I/O operation. After it, the node "fences" itself, and you will probably see a crash. It is calculated as the result of: (threshold - 1) x 2. Its default value is 31 (60 seconds). Raise it if you have slow disks and/or crashes with kernel messages like: o2hb_write_timeout: 164 ERROR: heartbeat write timeout to device XXXX after NNNN milliseconds O2CB Heartbeat threshold: `31` Loading filesystem "configfs": OK Mounting configfs filesystem at /sys/kernel/config: OK Loading stack plugin "o2cb": OK Loading filesystem "ocfs2_dlmfs": OK Mounting ocfs2_dlmfs filesystem at /dlm: OK Setting cluster stack "o2cb": OK Starting O2CB cluster ocfs2: OK
11.5.2. OCFS2ファイルシステムの使用
クラスタ構成を完了して、ファイルシステムを作成すると、他のファイルシステムと同様にマウントすることができます。
mount -t ocfs2 /dev/drbd0 /shared
dmesg コマンドで表示されるカーネルログに次のような行が見つかるはずです。
ocfs2: Mounting device (147,0) on (node 0, slot 0) with ordered data mode.その時点から、両方のノードでOCFS2ファイルシステムに読み取り/書き込みモードでアクセスできるようになります。
12. DRBDとXenの使用
この章では、Xenハイパーバイザを使用する仮想化環境のVBD (Virtual Block Device: 仮想ブロックデバイス)としてDRBDを使用する方法を説明します。
12.1. Xenの基礎
Xenはケンブリッジ大学(英国)で開発された仮想化フレームワークで、その後はXenSource, Inc. (現在はCitrix傘下)が維持管理しています。Debian GNU/Linux (バージョン4.0以降)、SUSE Linux Enterprise Server (リリース10以降)、 Red Hat Enterprise Linux (リリース5)など、ほとんどのLinuxディストリビューションの比較的新しいリリースにはXenが含まれています。
Xenでは準仮想化が使用されます。これは、仮想化ホストとゲスト仮想マシンの高度な協調を必要とする仮想化方式です。従来のハードウェアエミュレーションにもとづく仮想化ソリューションよりも高いパフォーマンスを実現します。適切な仮想化拡張機能をサポートするCPUの場合、Xenは完全なハードウェアエミュレーションもサポートします。これはXenの用語ではHVM (「Hardware-assisted Virtual Machine: ハードウェア支援仮想マシン」)と呼ばれます。
| 本書の執筆時点で、XenがHVM用にサポートするCPU拡張機能はIntelのVirtualization Technology (VT、以前のコードネームは「Vanderpool」)およびAMDのSecure Virtual Machine (SVM、以前の「Pacifica」)です。 |
Xenはライブマイグレーションをサポートします。これは、実行中のゲストオペレーティングシステムを1つの物理ホストからもう1つへ中断なく転送する機能です。
DRBDリソースをレプリケートされたXen用仮想ブロックデバイス(VBD)として設定すると、2つのサーバの両方でdomUの仮想ディスクとして使えます。さらに自動フェイルオーバさせることも可能になります。このように、DRBDは、仮想化以外の他の用途と同様に、Linuxサーバに冗長性を提供するだけでなく、Xenによって仮想化できる他のオペレーティングシステムにも冗長性を提供します。これには32ビットまたは64ビットIntel互換アーキテクチャで実行可能な実質上すべてのオペレーティングシステムが含まれます。
12.2. Xenとともに使用するためにDRBDモジュールパラメータを設定する
Xen Domain-0カーネルの場合は、 disable_sendpage を 1
に設定してDRBDモジュールをロードすることをお勧めします。ファイル /etc/modprobe.d/drbd.conf
を作成するか開いて、次の行を入力します。
options drbd disable_sendpage=112.3. Xen VBDとして適切なDRBDリソースを作成する
Xenの仮想ブロックデバイスとして使用するDRBDリソースの設定は比較的簡単です。基本的には、他の目的に使用するDRBDリソースの構成とほぼ同様です。ただし、ゲストインスタンスのライブマイグレーションを有効にしたい場合は、そのリソースのデュアルプライマリモードを有効にする必要があります。
resource <resource> {
net {
allow-two-primaries yes;
...
}
...
}デュアルプライマリモードを有効にするのは、Xenがライブマイグレーションを開始する前にすべてのVBDの書き込みアクセスをチェックするためです。リソースは、移行元ホストと移行先ホストの両方で使用されるように設定されます。
12.4. DRBD VBDの使用
DRBDリソースを仮想ブロックデバイスとして使用するには、Xen domU設定に次のような行を追加する必要があります。
disk = [ 'drbd:<resource>,xvda,w' ]この設定例では、 resource という名前のDRBDリソースを読み取り/書きみモード(w)で /dev/xvda
としてdomUで使用できるようにします。
もちろん、複数のDRBDリソースを単一のdomUで使用することもできます。その場合は、上記の例のように、コンマで区切って disk
オプションにさらに項目を追加します。
| ただし、次に示す3つの状況ではこの方法を使用できません。 |
-
完全に仮想化された(HVM) domUを構成する場合
-
グラフィカルインストールユーティリティを使用してdomUをインストールし、さらにそのグラフィカルインストーラが
drbd:構文をサポートしない場合。 -
kernel、initrd、extraオプションを指定せずにdomUを構成し、代わりにbootloaderとbootloader_argsによりXen擬似ブートローダを使用するように指定し、さらにこの擬似ブートローダがdrbd:構文をサポートしない場合。-
pygrub(Xen 3.3より前)およびdomUloader.py(SUSE Linux Enterprise Server 10のXenに同梱)は、仮想ブロックデバイス構成のdrbd:構文をサポートしない擬似ブートローダの例です。 -
Xen 3.3以降の
pygrubおよびSLES 11に同梱されるdomUloader.pyのバージョンはこの構文をサポートします。
-
このような場合は、従来の phy:
デバイス構文、およびリソース名ではなく、リソースに関連付けられたDRBDデバイス名を使用する必要があります。ただし、この場合はDRBDの状態遷移をXenの外部で管理する必要があるため、
drbd リソースタイプを使用する場合より柔軟性が低下します。
12.5. DRBDで保護されたdomUの開始、停止、移行
DRBDで保護されたdomUを設定したら、通常のdomUと同様に開始できます。
xm create <domU> Using config file "+/etc/xen/<domU>+". Started domain <domU>
このとき、VBDとして設定したDRBDリソースは、プライマリロールに昇格され、通常どおりにXenにアクセスできるようになります。
これも同様に簡単です。
xm shutdown -w <domU> Domain <domU> terminated.
この場合も、domUが正常にシャットダウンされると、DRBDリソースがセカンダリロールに戻ります。
これも通常のXenツールで実行します。
xm migrate --live <domU> <destination-host>
この場合、短時間に連続して複数の管理ステップが自動的に実行されます。
-
destination-host のリソースがプライマリロールに昇格されます。
-
domU のライブマイグレーションがローカルホストで開始します。
-
移行先ホストへの移行が完了すると、ローカル側でリソースがセカンダリロールに降格されます。
最初にリソースをデュアルプライマリモードに設定するのは、両方のリソースを短時間だけ両方のホストでプライマリロールとして実行する必要があるためです。
12.6. DRBDとXen統合の内部
Xenはネイティブで次のタイプの仮想ブロックデバイスをサポートします。
phyこのデバイスタイプは、ホスト環境で使用可能な「物理的な」ブロックデバイスをゲストdomUに基本的には透過的な方法で渡します。
fileこのデバイスタイプは、ファイルベースのブロックデバイスイメージをゲストdomUで使用するためのものです。元のイメージファイルからループブロックデバイスを作成し、このブロックデバイスを
phy デバイスタイプとほぼ同じ方法でdomUに渡します。
domU構成の disk オプションで設定された仮想ブロックデバイスが phy: と file:
以外の接頭辞を使用する場合、または接頭辞をまったく使用しない場合(この場合はXenのデフォルトの phy
デバイスタイプが使用される)は、Xenスクリプトディレクトリ(通常は /etc/xen/scripts )にある block
–prefix というヘルパースクリプトが使用されます。
DRBD はdrbdデバイスタイプ用のスクリプト( /etc/xen/scripts/block-drbd
)を提供しています。この章の前半で述べたように、このスクリプトは必要に応じてDRBDリソースの状態遷移を制御します。
12.7. XenとPacemakerの統合
DRBDで保護されるXen VBDのメリットを十分に活用するためにheartbeatを使用し、関連するdomUをheartbeatリソースとして管理することをお勧めします。
Xen domUをPacemakerリソースとして構成し、フェイルオーバを自動化することができます。これには Xen
OCFリソースエージェントを使用します。この章で説明したXenデバイスタイプとして drbd
を使用している場合は、Xenクラスタリソースで使用するために個別にdrbdリソースを設定する必要はありません。 block-drbd
ヘルパースクリプトによって必要なリソース移行がすべて実行されます。
DRBDパフォーマンスの最適化
13. ブロックデバイスのパフォーマンス測定
13.1. スループットの測定
DRBDを使用することによるシステムのI/Oスループットへの影響を測定する際には、スループットの絶対値はほとんど意味がありません。必要なのは、DRBDがI/Oパフォーマンスに及ぼす相対的な影響です。したがって、I/Oスループットを測定する際には、必ずDRBDがある場合とない場合の両方を測定する必要があります。
| ここで説明するテストは破壊的です。データが上書きされるため、DRBDデバイスの同期が失われます。したがって、テストが完了したら破棄することができるスクラッチボリュームに対してのみテストを行ってください。 |
I/Oスループットを見積もるには、比較的大きなデータチャンクをブロックデバイスに書き込み、システムが書き込み操作を完了するまでの時間を測定します。これは一般的なユーティリティ
dd を使用して簡単に測定できます。比較的新しいバージョンにはスループット見積もり機能が組み込まれています。
簡単な dd ベースのスループットベンチマークは、たとえば次のようになります。ここでは、 test
という名前のスクラッチリソースが現在接続されており、両方のノードでセカンダリロールになっています。
# TEST_RESOURCE=test
# TEST_DEVICE=$(drbdadm sh-dev $TEST_RESOURCE)
# TEST_LL_DEVICE=$(drbdadm sh-ll-dev $TEST_RESOURCE)
# drbdadm primary $TEST_RESOURCE
# for i in $(seq 5); do
dd if=/dev/zero of=$TEST_DEVICE bs=512M count=1 oflag=direct
done
# drbdadm down $TEST_RESOURCE
# for i in $(seq 5); do
dd if=/dev/zero of=$TEST_LL_DEVICE bs=512M count=1 oflag=direct
doneこのテストでは、512MのデータチャンクをDRBDデバイスに書き込み、次に比較のために下位デバイスに書き込みます。両方のテストをそれぞれ5回繰り返し、統計平均を求めます。結果は
dd が生成するスループット測定です。
新規に有効にしたDRBDデバイスの場合は、最初の dd
実行ではパフォーマンスがかなり低くなりますが、これは正常な状態です。アクティビティログがいわゆる「コールド」な状態のためで、問題はありません。
|
13.2. 待ち時間の測定
待ち時間を測定する際の対象はスループットベンチマークとはまったく異なります。I/O待ち時間テストでは、非常に小さいデータチャンク(理想的にはシステムが処理可能な最も小さいデータチャンク)を書き込み、書き込みが完了するまでの時間を測定します。通常はこれを何度か繰り返して、通常の統計変動を相殺します。
スループットの測定と同様に、I/O待ち時間の測定にも一般的な dd ユーティリティを使用できますが、異なる設定とまったく異なった測定を行います。
以下は簡単な dd ベースの待ち時間のマイクロベンチマークです。ここでは、 test
という名前のスクラッチリソースが現在接続されており、両方のノードでセカンダリロールになっています。
# TEST_RESOURCE=test
# TEST_DEVICE=$(drbdadm sh-dev $TEST_RESOURCE)
# TEST_LL_DEVICE=$(drbdadm sh-ll-dev $TEST_RESOURCE)
# drbdadm primary $TEST_RESOURCE
# dd if=/dev/zero of=$TEST_DEVICE bs=512 count=1000 oflag=direct
# drbdadm down $TEST_RESOURCE
# dd if=/dev/zero of=$TEST_LL_DEVICE bs=512 count=1000 oflag=directこのテストでは、512バイトのデータチャンクをDRBDデバイスに1,000回書き込み、次に比較のために下位デバイスにも1000回書き込みます。512バイトはLinuxシステム(s390以外のすべてのアーキテクチャ)が扱うことができる最小のブロックサイズです。
dd
が生成するスループット測定はこのテストではまったく意味がなく、ここで重要なのは、1,000回の書き込みが完了するまでにかかった時間です。この時間を1,000で割ると、1つのセクタへの書き込みの平均待ち時間を求めることができます。
14. DRBDのスループット最適化
この章では、DRBDのスループットの最適化について説明します。スループットを最適化するためのハードウェアに関する検討事項と、チューニングを行う際の詳細な推奨事項について取り上げます。
14.1. ハードウェアの検討事項
DRBDのスループットは、配下のI/Oサブシステム(ディスク、コントローラおよび対応するキャッシュ)の帯域幅とレプリケーションネットワークの帯域幅の両方の影響を受けます。
I/Oサブシステムのスループットは、主に平行して書き込み可能なディスクの数によって決まります。比較的新しいSCSIまたはSASディスクの場合、一般に1つのディスクに約40MB/sでストリーミング書き込みを行うことができます。ストライピング構成で配備する場合は、I/Oサブシステムにより書き込みがディスク間に並列化されます。 この場合、スループットは、1つのディスクのスループットに構成内に存在するストライプの数を掛けたものになります。RAID-0またはRAID-1+0構成で、 3つのストライプがある場合は同じ40MB/sのディスクのスループットが120MB/sになり、5つのストライプがある場合は200MB/sになります。
| ハードウェアのディスクミラーリング(RAID-1)は、一般にスループットにはほとんど影響ありません。ディスクのパリティ付きストライピング(RAID-5)はスループットに影響し、通常はストライピングに比べてスループットが低下します。 |
ネットワークスループットは一般にネットワーク上に存在するトラフィック量と経路上にあるルータやスイッチなどのスループットによって決定されます。ただし、DRBDのレプリケーションリンクは通常は専用の背面間ネットワーク接続であるため、これらはあまり関係がありません。したがって、ネットワークのスループットを向上させるには、高スループットのプロトコル(10ギガビットイーサネットなど)に切り換えるか、複数のネットワークリンクからなるリンク集積体を使用します。後者はLinux
bonding ネットワークドライバを使用して実現できます。
14.2. スループットオーバヘッドの予測
DRBDに関連するスループットオーバヘッドを見積もる際には、 必ず次の制限を考慮してください。
-
DRBDのスループットは下位I/Oサブシステムのスループットにより制限される。
-
DRBDのスループットは使用可能なネットワーク帯域幅により制限される。
理論上の最大スループットは上記の小さい方によって決まります。この最大スループットはDRBDのスループットオーバヘッドが加わることにより低下しますが、 これは3%未満だと考えられます。
-
たとえば、200MB/sのスループットが可能なI/Oサブシステムを持つ2つのクラスタノードが、 ギガビットイーサネットリンクで接続されているとします。TCP接続の場合、ギガビットイーサネットのスループットは110MB/s程度だと考えられるため、 この構成ではネットワーク接続が律速要因になります。DRBDの最大スループットは107MB/s程度になるでしょう。
-
一方、I/Oサブシステムの持続した書き込みスループットが100MB/s程度の場合は、これが律速要因となり、DRDBの最大スループットはわずか97MB/sになります。
14.3. チューニングの推奨事項
DRBDには、システムのスループットに影響する可能性があるいくつかの構成オプションがあります。ここでは、スループットを向上させるための調整について、いくつかの推奨事項を取り上げます。ただし、スループットは主としてハードウェアに依存するため、ここで取り上げるオプションを調整しても、効果はシステムによって大きく異なります。パフォーマンスチューニングについて、必ず効く「特効薬」は存在しません。
14.3.1. max-buffers と max-epoch-size の設定
これらのオプションはセカンダリノードの書き込みパフォーマンスに影響します。 max-buffers
はディスクにデータを書き込むためにDRBDが割り当てるバッファの最大数で、 max-epoch-size
は、2つの書き込みバリア間で許容される書き込み要求の最大数です。ほとんどの状況では、この2つのオプションを並行して同じ値に設定するのが適切です。パフォーマンスを上げるためには
max-buffers は max-epoch-size
以上でなければなりません。デフォルト値は両方とも2048です。比較的高パフォーマンスのハードウェアRAIDコントローラの場合、この値を8000程度に設定すれば十分です。
resource <resource> {
net {
max-buffers 8000;
max-epoch-size 8000;
...
}
...
}14.3.2. I/Oアンプラグ境界値の調整
I/Oアンプラグ境界値は、正常動作中にI/Oサブシステムのコントローラが「キックされる」(保留されたI/O要求を強制的に処理する)頻度に影響します。このオプションはハードウェアに大きく依存するため、一般的な推奨値はありません。
コントローラによっては、頻繁に「キックされる」とパフォーマンスが向上する場合があり、こうしたコントローラにはこの値を比較的小さく設定すると効果的です。DRBDで許容される最小値(16)まで小さくすることも可能です。キックされないほうがパフォーマンスが高くなるコントローラの場合は、この値を
max-buffers と同じ値まで大きくすることをお勧めします。
resource <resource> {
net {
unplug-watermark 16;
...
}
...
}14.3.3. TCP送信バッファサイズの調整
TCP送信バッファは送信TCPトラフィックのメモリバッファです。デフォルトサイズは128KiBです。高スループットネットワーク (専用ギガビットイーサネット、負荷分散ボンディング接続など)で使用する場合は、このサイズを512KiBかそれ以上に設定すると効果があるでしょう。送信バッファサイズを2MiB以上にすることは一般にはお勧めできません。 また、スループットが向上する可能性もありません。
resource <resource> {
net {
sndbuf-size 512k;
...
}
...
}TCP送信バッファの自動調整もサポートされます。この機能を有効にすると、DRBDが適切なTCP送信バッファサイズを動的に選択します。TCP送信バッファの自動調整を有効にするには、次のようにバッファサイズをゼロに設定します。
resource <resource> {
net {
sndbuf-size 0;
...
}
...
}14.3.4. アクティビティログサイズの調整
DRBDを使用するアプリケーションが、デバイス全体に分散した小さな書き込みを頻繁に発行する、書き込み集約型の場合は、十分に大きなアクティビティログを使用することをお勧めします。そうでない場合、頻繁なメタデータ更新により書き込みパフォーマンスが低下する可能性があります。
resource <resource> {
disk {
al-extents 3389;
...
}
...
}14.3.5. バリアとディスクフラッシュを無効にする
| 次に取り上げる推奨事項は、不揮発性(バッテリでバックアップされた)のコントローラキャッシュのあるシステムでのみで適用されます。 |
バッテリでバックアップされた書き込みキャッシュを持つシステムには、停電時にデータを保護する機能が組み込まれています。その場合は、同じ目的を持つDRBD自体の保護機能の一部を無効にすることもできます。これはスループットの面で有効な場合があります。
resource <resource> {
disk {
disk-barrier no;
disk-flushes no;
...
}
...
}15. DRBDの待ち時間の最適化
この章では、DRBDの待ち時間の最適化について説明します。待ち時間を最小にするためのハードウェアに関する検討事項と、チューニングを行う際の詳細な推奨事項について取り上げます。
15.1. ハードウェアの検討事項
DRBDの待ち時間は、配下のI/Oサブシステム(ディスク、コントローラおよび対応するキャッシュ)の待ち時間とレプリケーションネットワークの待ち時間の両方の影響を受けます。
I/Oサブシステムの待ち時間には、主としてディスクの回転速度が影響します。したがって、高速回転のディスクを使用すればI/Oサブシステムの待ち時間が短縮します。
同様に、BBWC (Battery-Backed Write Cache)を使用すると、書き込み完了までの時間が短くなり、書き込みの待ち時間を短縮できます。手頃な価格のストレージサブシステムの多くは何らかのバッテリバックアップキャッシュを備えており、管理者がキャッシュのどの部分を読み書き操作に使用するか設定できます。ディスク読み取りキャッシュを完全に無効にし、すべてのキャッシュメモリをディスク書き込みキャッシュとして使用する方法をお勧めします。
ネットワークの待ち時間は、基本的にはホスト間のRTT (Packet Round-Trip Time)です。これ以外にもいくつかの要因がありますが、そのほとんどは、DRBDレプリケーションリンクとして推奨する、DRBD専用回線接続の場合は問題になりません。ギガビットイーサネットリンクには常に一定の待ち時間が発生しますが、通常、これは100〜200マイクロ秒程度のパケット往復時間です。
ネットワークの待ち時間をこれより短くするには、待ち時間が短いネットワークプロトコルを利用する以外ありません。たとえば、Dolphin SuperSocketsのDolphin Expressなどを介してDRDBを実行します。
15.2. 待ち時間オーバヘッドの予測
スループットに関して、DRDBに関連する待ち時間オーバヘッドを見積もる際には、必ず次の制限を考慮してください。
-
DRBDの待ち時間は下位I/Oサブシステムの待ち時間により制限される。
-
DRBDの待ち時間は使用可能なネットワークの待ち時間により制限される。
DRBDの理論上の最小待ち時間は、上記2つの合計です。さらにわずかなオーバヘッドが追加されますが、これは1%未満だと予測されます。
-
たとえば、ローカルディスクサブシステムの書き込み待ち時間が3msで、ネットワークリンクの待ち時間が0.2msだとします。予測されるDRBDの待ち時間は3.2msで、ローカルディスクに書き込むだけのときと比べて約7%待ち時間が増加することになります。
| CPUのキャッシュミス、コンテキストスイッチなど、他にも待ち時間に影響する要因があります。 |
15.3. チューニングの推奨事項
15.3.1. CPUマスクの設定
DRBDでは、カーネルスレッドの明示的なCPUマスクを設定できます。これは、CPUサイクルがDRBDと競合するアプリケーションの場合に特に役立ちます。
CPUマスクは数字で、バイナリ表現の最下位ビットが第1のCPUを表し、その次のビットが第2のCPUを表します。ビットマスクの設定ビットは、対応するCPUがDRBDによって使用されていることを示し、クリアされたビットは使用されていないことを示します。たとえば、CPUマスク1
( 00000001 )は、DRBDが第1のCPUだけを使用することを示します。マスク12 ( 00001100
)はDRBDが第3と第4のCPUを使用することを示します。
次に、リソースのCPUマスク構成の例を示します。
resource <resource> {
options {
cpu-mask 2;
...
}
...
}| DRBDとこれを使用するアプリケーションとのCPU競合を最小限に抑えるためには、もちろん、DRBDが使用していないCPUだけをアプリケーションが使用するように設定する必要があります。 |
一部のアプリケーションは、DRBD自体と同様に設定ファイルでこの設定を行うことができます。アプリケーションによっては、initスクリプトで
taskset コマンドを呼び出す必要があります。
15.3.2. ネットワークMTUの変更
ブロックベースのファイルシステムがDRBDの上の層に置かれている場合は、レプリケーションネットワークのMTUサイズをデフォルトの1500バイトより大きい値に変更すると効果的な場合があります。(エクステントベースの場合は異なります)口語的には「ジャンボフレームを有効にする」といいます。
| ブロックベースのファイルシステムには、ext3、ReiserFS (バージョン3)およびGFSがあります。エクステントベースのファイルシステムには、XFS、LustreおよびOCFS2があります。エクステントベースのファイルシステムの場合は、少数の大きなファイルが格納されている場合を除き、ジャンボフレームを有効にしてもメリットはありません。 |
MTUは、次のコマンドを使用して変更できます。:
ifconfig <interface> mtu <size>
または
ip link set <interface> mtu <size>
<interface> にはDRBDのレプリケーションに使用するネットワークインタフェース名を指定します。 <size> の一般的値は9000 (バイト)です。
15.3.3. deadline deadline I/Oスケジューラを有効にする
高性能なライトバックに対応したハードウェアRAIDコントローラを使う場合、CFQの代わりに単純な deadline
をI/Oスケジューラに指定する方がDRBDの待ち時間を小さくできることがあります。比較的新しいカーネル構成(多くのディストリビューションでは2.6.18より後)ではデフォルトでは有効になっているCFQスケジューラよりも、こちらの使用をお勧めします。
I/Oスケジューラ構成に変更を加える場合は、 /sys にマウントされる sysfs 仮想ファイルシステムを使用できます。スケジューラ構成は
/sys/block/<device> に置かれています。<device>はDRBDが使用する下位デバイスです。
deadline スケジューラを有効にするには、次のコマンドを使用します。
echo deadline > /sys/block/<device>/queue/scheduler
次の値も設定することにより、さらに待ち時間を短縮できます。
-
フロントマージを無効にします。:
echo 0 > /sys/block/<device>/queue/iosched/front_merges
-
読み取りI/O deadlineを150ミリ秒にします(デフォルトは500ms)。
echo 150 > /sys/block/<device>/queue/iosched/read_expire
-
書き込みI/Oデッドラインを1500ミリ秒にします(デフォルトは3000ms)。
echo 1500 > /sys/block/<device>/queue/iosched/write_expire
上記の値の変更により待ち時間が大幅に改善した場合は、システム起動時に自動的に設定されるようにしておくと便利です。DebianおよびUbuntuシステムの場合は、 sysfsutils
パッケージと /etc/sysfs.conf 設定ファイルでこの設定を行うことができます。
グローバルI/Oスケジューラを選択するには、カーネルコマンドラインを使用して elevator
オプションを渡します。そのためには、ブートローダ構成(GRUBブートローダを使用する場合通常は /boot/grub/menu.lst
に格納)を編集し、カーネルブートオプションのリストに elevator=deadline を追加します。
DRBDをさらに詳しく知る
16. DRBDの内部
この章ではDRBDの内部アルゴリズムと内部構造について、いくつかの背景情報を取り上げます。これは、DRBDの背景について関心のあるユーザが対象です。DRBD開発者が参考にできるほど深い内容には踏み込んでいません。開発者の方は資料に記載された文書やDRBDリソースソースコードを参照してください。
16.1. DRBDメタデータ
DRBDはレプリケートするデータに関するさまざまな情報を専用の領域に格納しています。このメタデータには次のようなものがあります。
-
DRBDデバイスのサイズ
-
世代識別子(GI、詳細は世代識別子を参照)
-
アクティビティログ(AL、詳細はアクティビティログを参照)
-
クイック同期ビットマップ(詳細はクイック同期ビットマップを参照)
このメタデータは内部または外部に格納されます。いずれの方法で格納するかは、リソースごとに設定できます。
16.1.1. 内部メタデータ
内部メタデータを使用するようにリソースを設定すると、DRBDはメタデータを実際の本稼働データと同じ下位レベルの物理デバイスに格納します。デバイスの末尾の領域がメタデータを格納するための領域として確保されます。
メタデータは実際のデータと密接にリンクされているため、ハードディスクに障害が発生しても、管理者は特に何かする必要はありません。メタデータは実際のデータとともに失われ、ともに復元されます。
RAIDセットではなく、下位レベルデバイスが唯一の物理ハードディスクの場合は、内部メタデータが原因で書き込みスループットが低下することがあります。アプリケーションによる書き込み要求の実行により、DRBDのメタデータの更新が引き起こされる場合があります。メタデータがハードディスクの同じ磁気ディスクに格納されている場合は、書き込み処理によって、ハードディスクの書き込み/読み取りヘッドが2回余分に動作することになります。
| すでにデータが書き込まれているディスク領域を下位デバイスに指定してDRBDでレプリケートする場合で、内部メタデータを使うには、DRBDのメタデータに必要な領域を必ず確保してください。 |
そうでない場合、DRBDリソースの作成時に、新しく作成されるメタデータによって下位レベルデバイスの末尾のデータが上書きされ、既存のファイルが破損します。以下のいずれかの方法でこれを避けることができます。
-
下位レベルデバイスを拡張します。これには、LVMなどの論理ボリューム管理機能を使用します。ただし、対応するボリュームグループに有効な空き領域が必要です。ハードウェアストレージソリューションを使用することもできます。
-
下位レベルデバイスの既存のファイルシステムを縮小します。ファイルシステムによっては実行できない場合があります。
-
上記2つが不可能な場合は、代わりに外部メタデータを使用します。
下位レベルデバイスをどの程度拡張するか、またはファイルシステムをどの程度縮小するかについては、メタデータサイズの見積りを参照してください。
16.1.2. 外部メタデータ
外部メタデータは、本稼働データを格納するものとは異なる個別の専用ブロックデバイスに格納します。
一部の書き込み処理では、外部メタデータを使用することにより、待ち時間をいくらか短縮できます。
メタデータが実際の本稼働データに密接にリンクされません。つまり、ハードウェア障害により本稼働データだけが破損したか、DRBDメタデータは破損しなかった場合、手動による介入が必要です。生き残ったノードから切り替えるディスクに、手動でデータの完全同期を行う必要があります。
次の項目すべてに該当する場合には、外部メタデータ使用する以外の選択肢はありません。
-
DRBDでレプリケートしたい領域にすでにデータが格納されている。
-
この既存デバイスを拡張することができない。
-
デバイスの既存のファイルシステムが縮小をサポートしていない。
デバイスのメタデータを格納する専用ブロックデバイスが必要とするサイズにについてはメタデータサイズの見積りを参照してください。
| 外部メタデータには最小で1MBのデバイスサイズが必要です。 |
16.1.3. メタデータサイズの見積り
次の式を使用して、DRBDのメタデータに必要な領域を正確に計算できます。
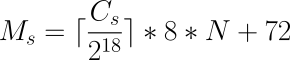
Cs はセクタ単位のデータデバイスサイズ、N は対向ノード数です。
デバイスサイズは blockdev --getsz <device> を実行して取得できます。
|
結果の Ms もセクタ単位です。MBに変換する場合は2048で割ります(521バイトをセクタサイズとする、s390を除くすべての標準のLinuxプラットフォームの場合)。
実際には、次の計算で得られる大まかな見積りで十分です。この式では、単位はセクタではなくメガバイトである点に注意してください。
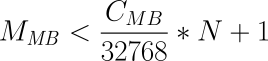
16.2. 世代識別子
DRBDでは世代識別子(GI)を使用してレプリケートされたデータの「世代」を識別します。
これはDRBDの内部メカニズムで、次のような目的で使用されます。
-
2つのノードが実際に同じクラスタのメンバか確認する(2つのノードが誤って接続されたものではないこと確認する)。
-
バックグラウンド同期の方向を確認する(必要な場合)。
-
完全な再同期が必要か、部分的な再同期で十分か判断する。
-
スプリットブレインを検出する。
16.2.1. データの世代
DRBDは次のような場合に、新しいデータ世代の開始としてマークを付けます。
-
デバイスの初期フル同期。
-
切断したリソースがプライマリロールに切り替わる。
-
プライマリロールのリソースが切断する。
つまり、リソースの接続状態が Connected になり、両方のノードのディスク状態が UpToDate になると、両方のノードの現在のデータ世代が同一になります。逆も同様です。現在の実装は、最下位ビットを使用してノードの役割(プライマリ/セカンダリ)をエンコードしていることに注意してください。よって、同じデータ世代でも、最下位ビットは異なることがあります。
新規のデータ世代は8バイトのUUID (Universally Unique Identifier)で識別されます。
16.2.2. 世代識別子タプル
DRBDでは、現在と履歴のデータ世代について4組の情報がローカルリソースメタデータに格納されます。
これは、ローカルノードからみた最新のデータ世代の世代識別子です。リソースが Connected になり完全に同期されると、両ノードの現在UUIDが同一になります。
これは、オンディスク同期ビットマップにより変更が追跡されている世代のUUIDです。オンディスク同期ビットマップ自体については、切断モードの間のみこの識別子が意味を持ちます。リソースが Connected の場合は、このUUIDは常に空(ゼロ)です。
これらは現在の世代より前の2つのデータ世代識別子です。
まとめて、これら4つを世代識別子タプル、または略して「GIタプル」と呼びます。
16.2.3. 世代識別子の変化
新規データ世代の開始
ネットワーク障害や手動の介入によりノードが対向ノードとの接続を失うと、DRBDは次のようにローカル世代識別子を変更します。

-
新規データ世代に対して新規UUIDが作成されます。これが、プライマリノードの新しい現在UUIDになります。
-
以前のUUIDは、ビットマップが変更を追跡している世代を参照します。したがって、これがプライマリノードの新しいビットマップUUIDになります。
-
セカンダリノードではGIタプルは変化しません。
再同期の開始
再同期を開始すると、DRBDはローカルの世代識別子に対して次のような変更を行います。

-
同期元の現在UUIDは変化しません。
-
同期元のビットマップUUIDが循環して、第1の履歴UUIDになります。
-
同期元で新規のビットマップUUIDが生成されます。
-
このUUIDが同期先の新しい現在UUIDになります。
-
同期先のビットマップUUIDと履歴UUIDは変化しません。
再同期の完了
再同期が完了すると、次のような変更が行われます。

-
同期元の現在UUIDは変化しません。
-
同期元のビットマップUUIDが循環して第1の履歴UUIDになり、第1のUUIDが第2の履歴UUIDに移動します。第2の履歴UUIDがすでに存在する場合は破棄されます。
-
次に、同期元のビットマップUUIDが空(ゼロ)になります。
-
同期先は、同期元からGIタプル全体を取得します。
16.2.4. 世代識別子とDRBDの状態
ノード間の接続が確立すると、2つのノードは現在入手可能な世代識別子を交換し、それに従って処理を続行します。結果は次のようにいくつか考えられます。
ローカルノードと対向ノードの両方で現在UUIDが空の状態です。新規に構成され、初回フル同期が完了していない場合は、通常この状態です。同期が開始していないため、手動で開始する必要があります。
対向ノードの現在UUIDが空で、自身は空でない場合です。これは、ローカルノードを同期元とした初期フル同期が進行中であることを表します。初期フル同期の開始時に、ローカルノードのDRBDはディスク上の同期ビットマップのすべてのビットを1にして、ディスク全体が非同期だと マークします。その後ローカルノードを同期元とした同期が始まります。逆の場合(ローカルの現在UUIDが空で、対向ノードが空でない場合)は、DRBDは同様のステップをとります。ただし、ローカルノードが同期先になります。
ローカルの現在UUIDと対向ノードの現在UUIDが空はなく、同じ値を持っている状態です。両ノードがともにセカンダリで、通信切断中にどのノードもプライマリにならなかったことを表します。この状態では同期は必要ありません。
ローカルノードのビットマップUUIDが対向ノードの現在UUIDと一致し、対向ノードのビットマップUUIDが空の状態です。これは、ローカルノードがプライマリで動作している間にセカンダリノードが停止して再起動したときに生じる正常な状態です。これは、リモートノードは決してプライマリにならず、ずっと同じデータ世代にもとづいて動作していたことを意味します。この場合、ローカルノードを同期元とする通常のバックグラウンド再同期が開始します。逆に、ローカルノード自身のビットマップUUIDが空で、対向ノードのビットマップがローカルノードの現在UUIDと一致する状態の場合。これはローカルノードの再起動に伴う正常な状態です。この場合、ローカルノードを同期先とする通常のバックグラウンド再同期が開始します。
ローカルノードの現在UUIDが対向ノードの履歴UUIDのうちの1つと一致する状態です。これは過去のある時点では同じデータを持っていたが、現在は対向ノードが最新のデータを持ち、しかし対向ノードのビットマップUUIDが古くなって使用できない状態です。通常の部分同期では不十分なため、ローカルノードを同期元とするフル同期が開始します。DRBDはデバイス全体を非同期状態とし、ローカルノードを同期先とするバックグラウンドでのフル再同期を始めます。逆の場合(ローカルノードの履歴UUIDのうち1つが対向ノードの現在UUIDと一致する)、DRBDは同様のステップを行いますが、ローカルノードが同期元となります。
ローカルノードの現在UUIDが対向ノードの現在UUIDと異なるが、ビットマップUUIDは一致する状態はスプリットブレインです。ただし、データ世代は同じ親を持っています。この場合、設定されていればDRBDがスプリットブレイン自動回復ストラテジが実行されます。設定されていない場合、DRBDはノード間の通信を切断し、手動でスプリットブレインが解決されるまで待機します。
ローカルノードの現在UUIDが対向ノードの現在UUIDと異なり、ビットマップUUIDも一致しない状態です。これもスプリットブレインで、しかも過去に同一のデータ状態であったという保証もありません。したがって、自動回復ストラテジが構成されていても役に立ちません。DRBDはノード間通信を切断し、手動でスプリットブレインが解決されるまで待機します。
最後は、DRBDが2つのノードのGIタプルの中に一致するものを1つも検出できない場合です。この場合は、関連のないデータと、切断に関する警告がログに記録されます。これは、相互にまったく関連のない2つのクラスタノードが誤って接続された場合に備えるDRBDの機能です。
16.3. アクティビティログ
16.3.1. 目的
書き込み操作中に、DRBDは書き込み操作をローカルの下位ブロックデバイスに転送するだけでなく、ネットワークを介して送信します。実用的な目的で、この2つの操作は同時に実行されます。タイミングがランダムな場合は、書込み操作が完了しても、ネットワークを介した転送がまだ始まっていないといった状況が発生する可能性があります。
この状況で、アクティブなノードに障害が発生してフェイルオーバが始まると、このデータブロックのノード間の同期は失われます。障害が発生したノードにはクラッシュ前にデータブロックが書き込まれていますが、レプリケーションはまだ完了していません。そのため、ノードが回復しても、このブロックは回復後の同期のデータセット中から取り除かれる必要があります。さもなくば、クラッシュしたノードは生き残ったノードに対して「先書き」状態となり、レプリケーションストレージの「オール・オア・ナッシング」の原則に違反してしまいます。これはDRBDだけでなく、実際、すべてのレプリケーションストレージの構成で問題になります。バージョン0.6以前のDRBDを含む他の多くのストレージソリューションでは、アクティブなノードに障害が発生した場合、回復後にそのノードを改めてフル同期する必要があります。
バージョン0.7以降のDRBDは、これとは異なるアプローチを採用しています。アクティビティログ(AL)は、メタデータ領域にに格納され、「最近」書き込まれたブロックを追跡します。この領域はホットエクステントと呼ばれます。
アクティブモードだったノードに一時的な障害が発生し、同期が行われる場合は、デバイス全体ではなくALでハイライトされたホットエクステントだけが同期されます。これによって、アクティブなノードがクラッシュしたときの同期時間を大幅に短縮できます。
16.3.2. アクティブエクステント
アクティビティログの設定可能なパラメータに、アクティブエクステントの数があります。アクティブエクステントは4MiB単位でプライマリのクラッシュ後に再送されるデータ量に追加されます。このパラメータは、次の対立する2つの状況の折衷案としてご理解ください。
大量のアクティビティログを記録すれば書き込みスループットが向上します。新しいエクステントがアクティブになるたびに、古いエクステントが非アクティブにリセットされます。この移行には、メタデータ領域への書き込み操作が必要です。アクティブエクステントの数が多い場合は、古いアクティブエクステントはめったにスワップアウトされないため、メタデータの書き込み操作が減少し、その結果パフォーマンスが向上します。
アクティビティログが小さい場合は、アクティブなノードが障害から回復した後の同期時間が短くなります。
16.3.3. アクティビティログの適切なサイズの選択
エクステントの数は所定の同期速度における適切な同期時間にもとづいて定義します。アクティブエクステントの数は次のようにして算出できます。
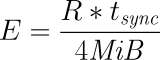
R はMB/秒単位の同期速度、 tsync は秒単位のターゲットの同期時間です。 E は求めるアクティブエクステントの数です。
スループット速度が90MiByte/秒のI/Oサブシステムがあり、同期速度が30MiByte/sに設定されているとします( R =30)。ターゲットの同期時間は4分(240秒)を維持する必要があります。( tsync =240):
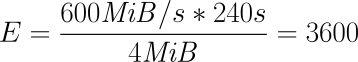
正確な計算結果は1800ですが、DRBDのAL実装のハッシュ関数はエクステントの数が素数に設定されている場合に最適に動作します。したがって、ここでは1801を選択します。
16.4. クイック同期ビットマップ
クイック同期ビットマップはDRBDがリソースごとに使用する内部データ構造で、同期ブロック(両方のノードで同一)または非同期ブロックを追跡します。ビットマップはノード間通信が切断しているときのみ使われます。
クイック同期ビットマップでは、1ビットが4KiBチャンクのオンディスクデータを表します。ビットがクリアされていれば、対応するブロックが対向ノードと同期しています。つまり、切断以降、ブロックに書き込まれていないということです。逆に、ビットが設定されていればブロックが変更されているため、接続が再確立したらすぐに再同期を行う必要があります。
スタンドアロンノードでディスクにデータが書き込まれると、クイック同期ビットマップのへの書き込みも始まります。ディスクへの同期的なI/Oは負荷が大きいため、実際にはメモリ上のビットマップのビットが設定されます。アクティビティログ)が期限切れになってブロックがコールドになると、メモリ上のビットマップがディスクに書き込まれます。同様に、生き残ったスタンドアロンのノードでリソースが手動でシャットダウンされると、DRBDはすべてのビットマップをディスクにフラッシュします。
リモートノードが回復するか接続が再確立すると、DRBDは両方のノードのビットマップ情報を照合して、再同期が必要なすべてのデータ領域を決定します。同時に、DRBDは世代識別子を調べ、同期の方向を決定します。
同期元ノードが同期対象ブロックを対向ノードに送信し、同期先が変更を確認すると、ビットマップの同期ビットがクリアされます。別のネットワーク障害などで再同期が中断し、その後再開すると、中断した箇所から同期を続行します。 — 中断中にブロックが変更された場合、もちろんそのブロックが再同期データセットに追加されます。
drbdadm pause-sync と drbdadm resume-sync
コマンドを使用して、再同期を手動で一時停止したり再開することもできます。ただしこれは慎重に行ってください。再同期を中断すると、セカンダリノードのディスクが必要以上に長く
Inconsistent 状態になります。
|
16.5. peer fencingインタフェース
DRBDは、レプリケーションリンクが遮断したときに、対向ノードを切り離すメカニズムとして定義されたインタフェースを備えています。Heartbeatに同梱の
drbd-peer-outdater ヘルパーはこのインタフェースのリファレンス実装です。ただし、独自のpeer
fencingヘルパープログラムも簡単に実装できます。
fencingヘルパーは次のすべてを満たす場合にのみ呼び出されます。
-
リソース(またはcommon)の
handlersセクションでfence-peerハンドラが定義されている。 -
fencingオプションで、resource-onlyまたはresource-and-stonithが設定されている。 -
レプリケーションリンクの中断時間が、DRBDがネットワーク障害を検出するために十分である。
fence-peer ハンドラとして指定されたプログラムかスクリプトが呼び出されると、 DRBD_RESOURCE と DRBD_PEER
環境変数が利用できるようになります。これらの環境変数には、それぞれ、影響を受けるDRBDリソース名と対向ホストのホスト名が含まれています。
peer fencingヘルパープログラム(またはスクリプト)は、次のいずれかの終了コードを返します。
| 終了コード | 意味 |
|---|---|
3 |
対向ノードのディスク状態がすでに Inconsistent になっている。 |
4 |
対向ノードのディスク状態が正常に Outdated に設定された(または最初から Outdated だった。) |
5 |
対向ノードへの接続に失敗。対向ノードに到達できなかった。 |
6 |
影響を受けるリソースがプライマリロールになっていたため、対向ノードを無効にできなかった。 |
7 |
対向ノードがクラスタから正常にフェンシングされた。影響を受けるリソースの |
17. 詳細情報の入手
17.1. 商用DRBDのサポート
DRBDの商用サポート、コンサルティング、トレーニングサービスは、プロジェクトのスポンサ企業LINBIT社が提供しています。日本では LINBIT 社との提携にもとづいてサイオステクノロジー株式会社が各種サポートを提供しています。
17.2. 公開メーリングリスト
DRBDの一般的な使用法について質問がある場合は、公開メーリングリスト [email protected] にお問い合せください。このメーリングリストは登録が必要です。 http://lists.linbit.com/drbd-user で登録してください。すべてのアーカイブのリストは http://lists.linbit.com/pipermail/drbd-user にあります。
17.3. 公開IRCチャンネル
公開IRCサーバ irc.freenode.net の次のチャンネルに、DRBDの開発者も参加しています。
-
#drbd, -
#linux-ha, -
#linux-cluster.
IRCを使って、DRBDの改善を提案したり、開発者レベルの議論をするときもあります。
17.5. 資料
DRBDの開発者により作成されたDRBD一般やDRBDの特定の機能についての文書が公開されています。その一部を次に示します。
-
Lars Ellenberg. ‘DRBD v8.0.x and beyond’. 2007. Available at http://www.drbd.org/fileadmin/drbd/publications/drbd8.linux-conf.eu.2007.pdf
-
Philipp Reisner. ‘DRBD v8 – Replicated Storage with Shared Disk Semantics’. 2007. Available at http://www.drbd.org/fileadmin/drbd/publications/drbd8.pdf.
-
Philipp Reisner. ‘Rapid resynchronization for replicated storage’. 2006. Available at http://www.drbd.org/fileadmin/drbd/publications/drbd-activity-logging_v6.pdf
17.6. その他の資料
-
Wikipedaにはhttp://en.wikipedia.org/wiki/DRBD[an entry on DRBD]があります。
-
ClusterLabsに、高可用性クラスタでDRBDを活用するための有益な情報があります。
付録
付録 A: 新しい変更点
この付録はDRBD 8.4より前のバージョンからアップグレードしたユーザ向けです。DRBDの構成と挙動へのいくつかの重要な変更点に焦点を合わせています。
A.1. ボリューム
ボリュームはDRBD 8.4の新しい概念です。8.4より前では、すべてのリソースは1つのブロックにのみ関連付けられていました。そのためDRBDデバイスとリソース間は1対1の関係でした。8.4からは各々が1つのブロックデバイスに対応するマルチボリュームが、1つのレプリケーションコネクションを共有することが可能になりました。これは順番に1つのリソースに対応するものです。
A.1.1. udevシンボリックリンクの変更
DRBD udev統合スクリプトは、個々のブロックデバイスのノードを示すシンボリックリンクを管理します。これらは /dev/drbd/by-res
と /dev/drbd/by-disk ディレクトリにあります。
DRBD 8.3以前では、 /dev/drbd/by-disk のリンクは1つのブロックデバイスに張られていました。
lrwxrwxrwx 1 root root 11 2011-05-19 11:46 /dev/drbd/by-res/home -> ../../drbd0 lrwxrwxrwx 1 root root 11 2011-05-19 11:46 /dev/drbd/by-res/data -> ../../drbd1 lrwxrwxrwx 1 root root 11 2011-05-19 11:46 /dev/drbd/by-res/nfs-root -> ../../drbd2
DRBD 8.4では、1つのリソースが複数ボリュームに対応できるため、 /dev/drbd/by-res/<resource>
は個々のボリュームに張られたシンボリックを含むディレクトリになりました。
lrwxrwxrwx 1 root root 11 2011-07-04 09:22 /dev/drbd/by-res/home/0 -> ../../drbd0 lrwxrwxrwx 1 root root 11 2011-07-04 09:22 /dev/drbd/by-res/data/0 -> ../../drbd1 lrwxrwxrwx 1 root root 11 2011-07-04 09:22 /dev/drbd/by-res/nfs-root/0 -> ../../drbd2 lrwxrwxrwx 1 root root 11 2011-07-04 09:22 /dev/drbd/by-res/nfs-root/1 -> ../../drbd3
シンボリックリンクが参照するファイルシステムの構成は、DRBD 8.4に移行する場合には、通常は単純にシンボリックリンクのパスに /0
を追加することで更新されている必要があります。
A.2. 構成における構文の変更点
このセクションでは構成における構文の変更点について扱います。これは /etc/drbd.d と /etc/drbd.conf
のDRBD設定ファイルに影響があります。
drbdadm
の構文解析は8.4より前の構文も受け付け、現在の構文へ内部で自動的に変換します。前のリリースにない新機能の使用を行うのでなければ、現在の構文に合わせて構成を調整する必要はありません。しかしながら、DRBD
9では旧フォーマットはサポートされなくなるため、いずれは新しい構文を適用することを推奨いたします。
|
A.2.1. 論理型構成オプション
drbd.conf は色々な論理型構成オプションをサポートしています。DRBD 8.4より前の構文では、これら論理型オプションは次のようでした。
resource test {
disk {
no-md-flushes;
}
}これは構成上の問題がありました。 common 構成セクションに論理型オプションを加えたいとき、その後で個々のリソースを上書きしていました。
common セクションに論理型オプションが付いた構成例common {
no-md-flushes;
}
resource test {
disk {
# No facility to enable disk flushes previously disabled in
# "common"
}
}DRBD 8.4では、すべての論理型オプションは yes か no の値をとります。 common からでも個々の resource
セクションからでも、これらオプションが操作しやすくなっています。
common セクションでのDRBD 8.4の論理型オプション付き構成例common {
md-flushes no;
}
resource test {
disk {
md-flushes yes;
}
}A.2.2. syncer セクションはなくなりました
DRBD 8.4より前では、構成の構文で syncer セクションが使用できましたが、8.4では使われなくなりました。以前あった syncer
オプションは、リソースの net または disk セクションの中に移動しています。
syncer セクション付きの構成例resource test {
syncer {
al-extents 3389;
verify-alg md5;
}
...
}上記の例で表しているものは、DRBD 8.4の構文では次のようになります。
resource test {
disk {
al-extents 3389;
}
net {
verify-alg md5;
}
...
}A.2.3. protocol オプションは特例でなくなりました
以前のDRBDリリースでは、 protocol オプションは不自然にも(また直観に反して)、 net
セクション内ではなく、単独で定義される必要がありました。DRBD 8.4ではこの変則をなくしています。
protocol オプションのある構成例resource test {
protocol C;
...
net {
...
}
...
}DRBD 8.4での同じ構成の構文は次のようになります。
net セクション内に protocol オプションのあるDRBD 8.4構成例resource test {
net {
protocol C;
...
}
...
}A.2.4. 新しいリソースごとの options セクション
DRBD 8.4では、 resource セクション内でも common セクション内でも定義できる新しい options
セクションを導入しました。以前は不自然にも syncer セクションで定義されていた cpu-mask
オプションは、このセクションに移動しました。同様に8.4より前のリリースでは disk セクションで定義されていた
on-no-data-accessible オプションもこのセクションに移動しました。
cpu-mask と on-no-data-accessible オプションのある構成例resource test {
syncer {
cpu-mask ff;
}
disk {
on-no-data-accessible suspend-io;
}
...
}DRBD 8.4での同じ構成の構文は次のようになります。
options セクションでのDRBD 8.4の構成例resource test {
options {
cpu-mask ff;
on-no-data-accessible suspend-io;
}
...
}A.3. ネットワーク通信のオンライン変更
A.3.1. レプリケーションプロトコルの変更
DRBD 8.4より前では、リソースがオンラインまたはアクティブの状態では、レプリケーションプロトコルの変更は不可能でした。リソースの構成ファイル内で
protocol オプションを変更し、それから両ノードで drbdadm disconnect を実行し、最後に drbdadm
connect を行わなければなりませんでした。
DRBD 8.4では、即座にレプリケーションプロトコルの変更が行えます。たとえば、一時的に接続を通常の同期レプリケーションから非同期レプリケーションのモードに変更することができます。
drbdadm net-options --protocol=A <resource>
A.3.2. シングルプライマリからデュアルプライマリのレプリケーションに変更する
DRBD
8.4より前では、リソースがオンラインやアクティブの状態ではシングルプライマリからデュアルプライマリに変更したり戻したりする事はできませんでした。リソースの構成ファイル内の
allow-two-primaries オプションを変更し、 drbdadm disconnect を実行し、それから drbdadm
connect を両ノードで実行する必要がありました。
DRBD 8.4ではオンラインで変更が行えます。
| DRBDのデュアルプライマリモードを使うアプリケーションはクラスタファイルシステムまたは他のロッキング機構を使用していることが必要です。このために、デュアルプライマリモードが一時的または永続的であることは区別されません。 |
リソースがオンライン中にデュアルプライマリに変更する場合は、一時的なデュアルプライマリモードを参照してください。
A.4. drbdadm コマンドの変更点
A.4.1. pass-throughオプションの変更点
DRBD 8.4以前では、 drbdadm で特殊なオプションを drbdsetup に引き渡す場合には、次の例のように難解な
-- --<option> 構文を使わなければなりませんでした。
drbdadm の引き渡しオプションdrbdadm -- --discard-my-data connect <resource>
代わりに、 drbdadm はこの引き渡しオプションを通常オプションと同じように使えるようになりました。
drbdadm 引き渡しオプションdrbdadm connect --discard-my-data <resource>
古い構文もまだサポートされますが、使わないことを強くお勧めします。なお、この新しい簡単な構文を使用する場合には、(
--discard-my-data )オプションを、( connect )サブコマンドの後で、かつリソース識別子の前に指定する必要があります。
|
A.4.2. --overwrite-data-of-peer は --force オプションに置き換えられました
--overwrite-data-of-peer オプションはDRBD 8.4ではなくなり、より簡潔な --force
に置き換えられました。このため、リソースの同期を開始するために、次のコマンドは使えません。
drbdadm 同期開始コマンドdrbdadm -- --overwrite-data-of-peer primary <resource>
代わりに次のようなコマンドをご使用ください。
drbdadm 同期開始コマンドdrbdadm primary --force <resource>
A.5. デフォルト値の変更点
DRBD 8.4では、Linuxカーネルや利用できるサーバハードウェアの向上に合わせて、 drbd.conf
のいくつかのデフォルト値が更新されました。
A.5.1. 同時にアクティブなアクティビティログのエクステント数( al-extents )
al-extents
の以前のデフォルト値の127は1237に変更になりました。これによりメタデータのディスク書き込み作業量の現象によるパフォーマンスの向上が可能になりました。この変更によりプライマリノードのクラッシュ時の再同期時間が長くなります。これはギガビットイーサネットと高帯域幅のレプリケーションリンクの偏在が関係しています。
A.5.2. ランレングス符号化( use-rle )
画像転送のためのランレングス符号化(RLE)がDRBD 8.4ではデフォルトで有効になっています。 use-rle オプションのデフォルト値は
yes
です。RLEは、2つの切断されたノードの接続時に常に起きるクイック同期ビットマップ中のデータ転送量を大きく減らします。
A.5.3. I/Oエラーの処理ストラテジー( on-io-error )
DRBD 8.4ではデフォルトでI/Oスタックの上位レイヤにI/Oエラーを伝えない設定です。以前のバージョンではI/Oエラーを伝える設定でしたが、置き換えられました。つまり問題のあるドライブのDRBDボリュームが自動的に Diskless のディスク状態に遷移し、対向ノードからのデータを提供します。
A.5.4. 可変レート同期
可変レート同期はDRBD 8.4ではデフォルトで有効です。デフォルト設定は次の構成のようになっています。
resource test {
disk {
c-plan-ahead 20;
c-fill-target 50k;
c-min-rate 250k;
}
...A.5.5. 構成可能なDRBDデバイス数( minor-count )
DRBD 8.4で構成可能なDRBDデバイス数は1,048,576 (2$^{20}$)です(前バージョンでは255)。これは生産システムでの想定を越える、理論的な限界以上のものです。