Open Source Software-Defined Storage Management
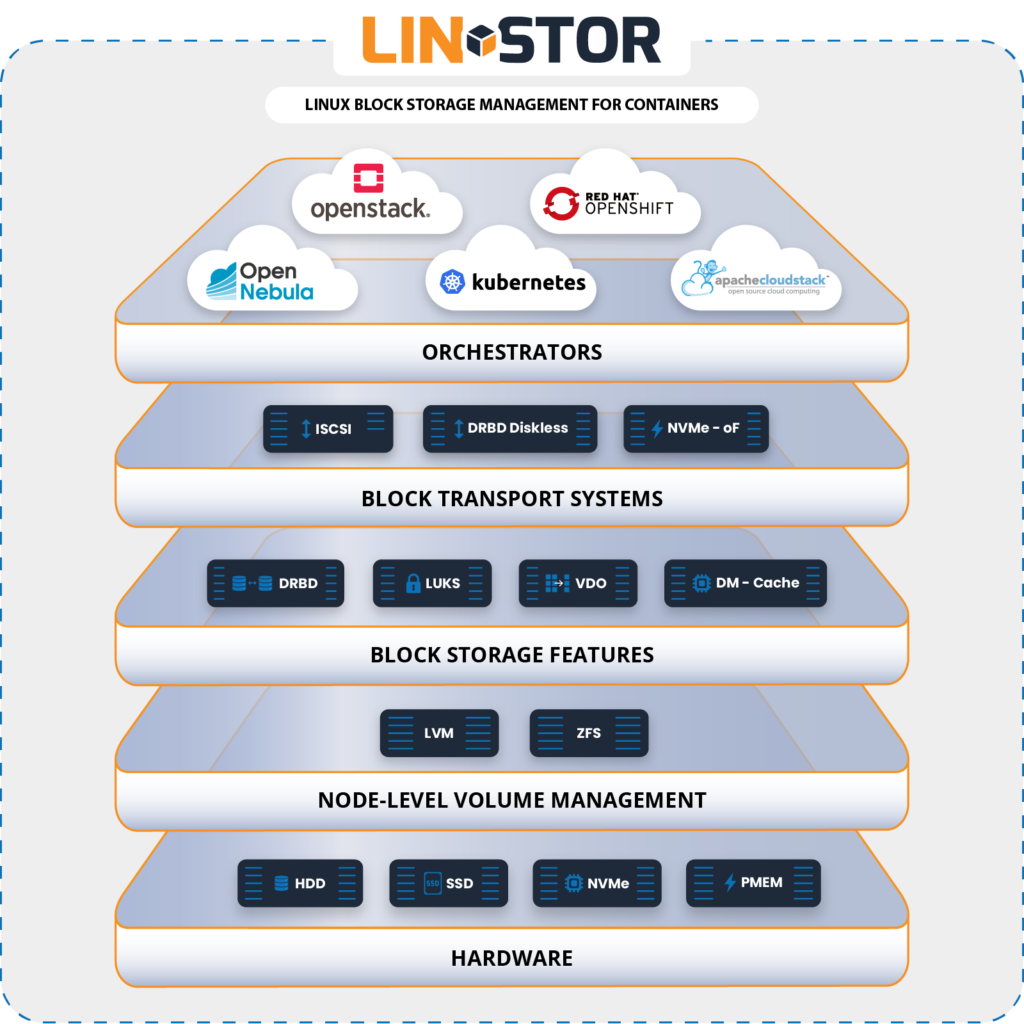
LINSTOR has multiple uses, but it is typically used to manage a large number of DRBD replicated storage resources to ensure high availability and proven high performance for data that your applications and services depend on. LINSTOR integrates with many platforms, including Kubernetes, CloudStack, Docker, OpenNebula, Proxmox VE, and more.
LINSTOR’S MISSION
The mission of LINSTOR is to make it easier and more efficient to manage software-defined storage resources within Linux clusters and bring high availability and high performance to the data that your applications depend on.
LINSTOR is a flexible solution and you can use it on bare-metal clusters, in a cloud or hybrid cloud, virtualized, or in containers. You can also integrate LINSTOR with many platforms, such as Kubernetes, CloudStack, Docker, OpenNebula, Proxmox VE, and others. By using LINSTOR’s native integrations, you can build, run, and control persistent block storage solutions in these platforms more simply. You can also bring data storage features to platforms that you might not otherwise be able to, such as high availability (by using DRBD), and disaster recovery (by using snapshot shipping).
To make deploying and running LINSTOR hassle-free, LINBIT® offers an enterprise subscription, LINBIT SDS, which includes LINSTOR, DRBD, related software utilities, and expert support from LINBIT engineers and developers. From planning to production, LINBIT can help you and your operations team succeed with LINBIT SDS.
Fastest Persistent Storage


The Science of the System
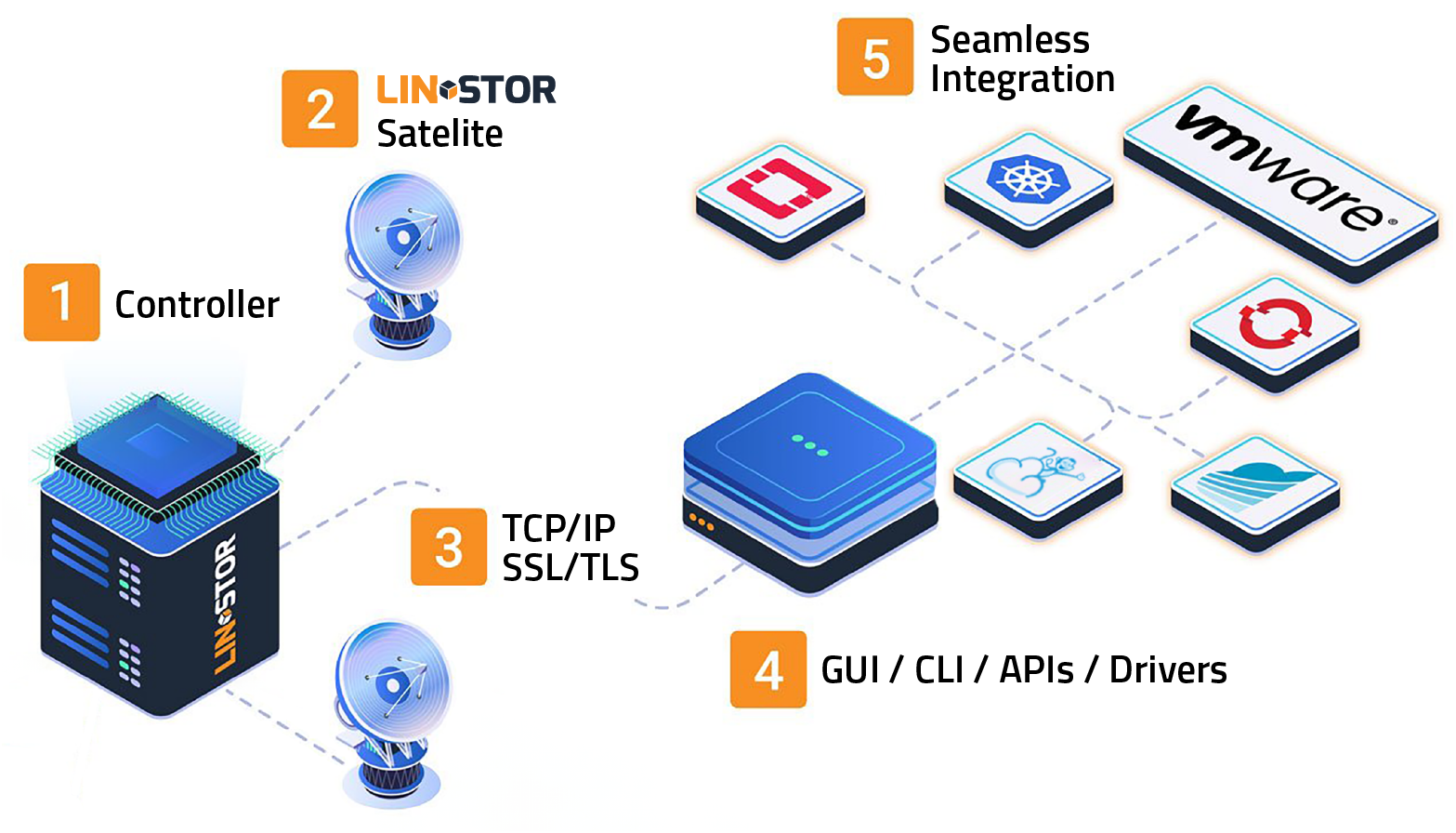
Controller, Satellite, and User Interface
The LINSTOR® system consists of multiple server and client components.
- A LINSTOR controller manages the configuration of the LINSTOR cluster and all its managed storage resources
- The LINSTOR satellite component manages the creation, modification, and deletion of storage resources on each node that provides or uses LINSTOR-managed storage resources
- All communication between LINSTOR components use LINSTOR’s network protocol, based on TCP/IP network connections
- Manage the storage system by using a command-line utility to interact with the active LINSTOR controller.
- Alternatively, integrate the LINSTOR system into the storage architecture of other software systems, such as Kubernetes
Controller, Satellite, and User Interface
The LINSTOR® system consists of multiple server and client components.
- A LINSTOR controller manages the configuration of the LINSTOR cluster and all its managed storage resources
- The LINSTOR satellite component manages the creation, modification, and deletion of storage resources on each node that provides or uses LINSTOR-managed storage resources
- All communication between LINSTOR components use LINSTOR’s network protocol, based on TCP/IP network connections
- The storage system can be managed by directly using a GUI or a command line utility to interact with the active LINSTOR controller. Alternatively, users may integrate the LINSTOR system into the storage architecture of other software systems, such as Kubernetes
- Alternatively, integrate the LINSTOR system into the storage architecture of other software systems, such as Kubernetes
Key Features
Simplify the management of storages volumes
Full Integration with Container Ecosystem

HA Controller & Replication link

Separation of Data & Control plane

Ideal for hyper-converged VM workloads

Open Source
Full Integration with Container Ecosystem
HA Controller & Replication link
Separation of Data & Control plane
Full Integration with Container Ecosystem
HA Controller & Replication link
Built With Developers In Mind
LINSTOR® has a container storage interface (CSI) driver for Kubernetes and is compatible with OpenShift. LINSTOR can also be used independently of a cloud, virtualization, or container platform to manage large DRBD clusters.

Built With Developers In Mind
LINSTOR® has a container storage interface (CSI) driver for Kubernetes and is compatible with OpenShift. LINSTOR can also be used independently of a cloud, virtualization, or container platform to manage large DRBD clusters.

Your Benefits

Engineering Time

User Friendly UI
Business Data




