Remote Direct Memory Access (RDMA) is a data transport protocol that has changed the way data is transferred over networks. This article will discuss the topic of RDMA, what it is, how it differs from Transmission Control Protocol (TCP), and why you might want to use it in a high availability (HA) data replication topology. You will also learn how to install RDMA packages on Red Hat Enterprise Linux and Ubuntu Linux so that you can implement RDMA on storage servers, for example.
Comparing RDMA with TCP
To understand and appreciate RDMA, it might be best to first discuss another data transport protocol: TCP.
TCP Background
TCP has been a solid transport protocol for a long time and delivers what it promises, that is, ordered, reliable, and complete delivery of data that arrives at its destination with the same integrity as it left its source. However, this reliable transport protocol has some costs, mostly computational, which can have a negative impact on latency and system performance.
For nearly all Linux setups, the Linux kernel is tasked with delivering data sent via TCP in order and without losing any data. The TCP transport has to copy the outgoing data into some buffers to send these messages, which takes time. If a data packet for some reason is not successfully sent or acknowledged as received, TCP can retry the send from its buffered copy. However, there is much context switching with TCP data transmission as the system makes application calls between user space and kernel space for the copy operations. There is a good IBM article on this topic if you want to learn more.
TCP Computational Overhead
These copy functions, moving data into and out of buffers and in different contexts, cause one of the major bottlenecks for network I/O: the increased demand on the CPU for these computational tasks. With TCP, you can begin to experience system performance degradation when you reach 10 gigabits per second (Gbps) data transfer speeds. System performance continues to severely degrade from there on. In addition, all these copy functions increase latency, that is, the time from when data is sent to when it is received. In a storage system, this negatively affects that all-important IOPS number that you might be targeting. This topic is discussed in the DRBD® User Guide in the “Latency Compared to IOPS” section.
Yes, there are zero-copy sending solutions that you can implement for TCP, such as sendfile and mmap. However, on the receiving side of a network attached storage system, the fragments have to be accumulated, sorted, and merged into buffers so that the storage devices (hard disk drives or solid state drives) can do their direct memory access (DMA) from continuous 4KiB pages. And while specialized hardware such as TCP offload engine (TOE) network controllers are available and can help by offloading the kernel space work to a network controller, this technology might cause as many problems as it solves, with the added complexity and potential security concerns.
RDMA Background
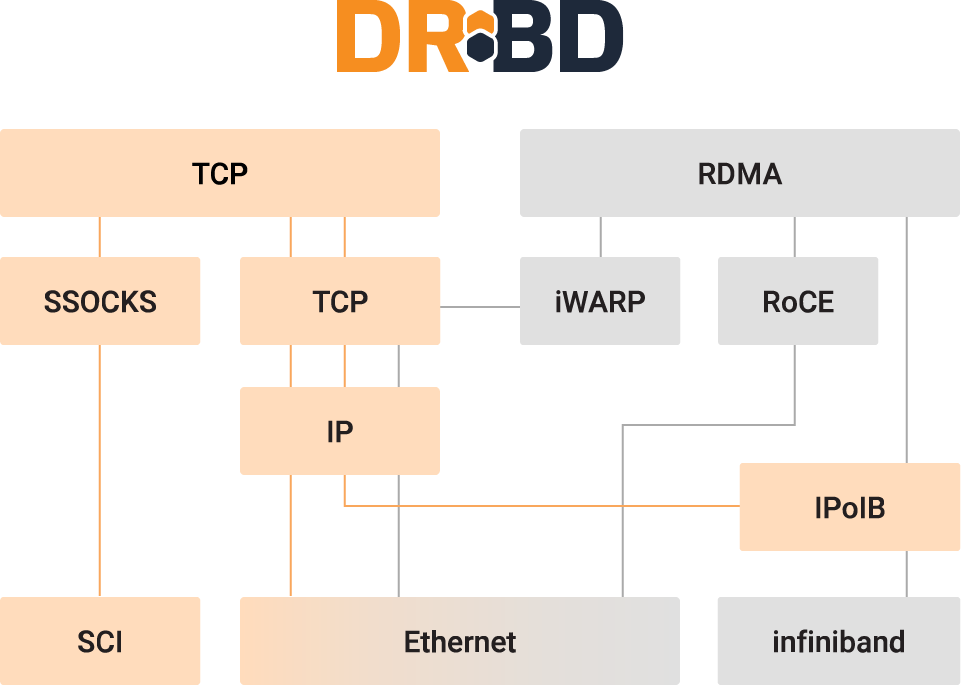
In contrast to TCP, RDMA uses specialized hardware to bypass the traditional TCP/IP layer stack. By implementing RDMA you can directly move data from the physical memory in one machine to the physical memory in another, by using RDMA compatible hardware as the conduit, without involving the CPU (apart from specifying what should be sent via the transport protocol).
RDMA comes in various forms and implementations such as InfiniBand, iWarp, and RDMA over Converged Ethernet (RoCE). In some cases, these implementations have different on-wire protocols. For example, RoCE and iWarp use IP networks to transport data and their traffic can therefore be routed. In this sense, you might think of these implementations as “just” advanced offload engines.
The common and important point is that the sending system does not have to “ask” its CPU to split the data up into MTU-sized chunks. Nor does the receiving system have to ask its CPU to join the received data streams back together (to get a single, aligned, 4KiB page that can be transmitted to storage, for example). Rather, an imagined RDMA dialog between sender and receiver might be: “Here are 16 memory pages of 4KiB, store data coming from this channel into these pages the next time,” and “Push those 64KiB across this channel.” This means actual zero-copy send and receive and much lower latency.
Single Root I/O Virtualization
Some hardware allows splitting a physical networking device into multiple virtual ones. This feature is called Single Root I/O Virtualization (SR-IOV). On a practical level, it means that a virtual machine can push memory pages directly to another machine without involving the hypervisor operating system or copying data around in buffers. Needless to say that this improves performance quite a bit, as compared to cutting data into pieces and moving them through the hypervisor.
RDMA over Converged Ethernet
RDMA over Converged Ethernet (RoCE) is a network protocol that uses the power of RDMA to accelerate the communication between applications hosted on clustered servers and storage arrays that are connected on Ethernet networks. RoCE allows devices to directly transfer data from memory to memory without involving the host CPU. Instead, the transport processing, and memory translation and placement are done by hardware. This lowers latency and increases performance compared to other software protocols.
Some of the most popular uses for RoCE include private cloud environments, because the reduced demand on the CPU can be used for other computational processes such as running virtual machines. Other uses for RoCE include big data analytics, data warehousing, high-performance computing, and financial services because it allows for faster data transmission and data processing speeds.
The Benefits of Using RDMA
As mentioned earlier, the primary advantage of using RDMA over other software-based protocols is that you avoid the bottleneck of putting too many tasks on a CPU during data transfer. By avoiding bottlenecks that you would have by using TCP, you increase speed, lower latency, and increase overall system performance. RDMA variants such as Ethernet InfiniBand are common and they can provide data transfer speeds of 10 to 100 Gbps. These speeds and the reduced latency and processing needed for data transfer are very welcome when you are hosting and running processes on large data sets or complex or high-speed computational processes. Increasingly common examples of these types of processes include machine learning, complex systems modeling, and real-time data processing such as what might be needed for financial services processing.
As with everything though, RDMA has its downsides. These include the high level of upfront investments which are usually necessary to deploy RDMA. There are many requirements to deploy RDMA, the most expensive being the network interface controllers (NICs) and network switches that support RDMA. All systems on the same network must support the protocol. If you make your systems highly available, equipment redundancy will also add to your investment costs. However, over time you might lower your total costs of ownership, by reducing the power consumption, and wear-and-tear on physical hardware.
Using NVMe with RDMA
It would be silly to implement RDMA technology in your deployment but neglect to consider your storage media. Storage media is, after all, where the data that you are concerned about transferring usually lives. You might theoretically increase data transfer speeds and reduce latency by implementing RDMA, just to have slower storage media become a bottleneck. This is where non-volatile memory express (NVMe) capable storage drives, and in particular so-called “high-performance” NVMe drives, typically come in. NVMe is a data transfer protocol associated with storage media, usually solid-state drives. Similar to RDMA, NVMe offers increased transfer speeds, greater queue depth, and reduced latency, when compared to other technologies such as Serial Attached SCSI (SAS) or Advanced Host Controller Interface (AHCI) used by SATA storage media.
While there are other high-performance storage media such as storage-class memory (SCM) and persistent memory (PMEM) devices, they usually cost more than NVMe storage media. Therefore, deploying NVMe storage might be a minimum and the most popular entry point when implementing RDMA.
Where RDMA Is Used
Organizations use RDMA anywhere low latency and high throughput are needed. Two common RDMA implementations are iSCSI Extensions for RDMA (iSER) and NVMe over Fabrics (NVMe-oF).
iSER
The iSER network protocol implements iSCSI (a TCP/IP based protocol) by using RDMA. This implementation is popular because data transfer between an iSCSI initiator and an iSCSI target can happen over Ethernet connections. These likely already exist in someone’s deployment and an organization would not have the additional expense of investing in and deploying new network connections.
NVMe-oF
Another common RDMA implementation is NVMe-oF. As the name implies, NVMe-oF uses NVMe storage transfer protocols over “fabrics” where fabrics are the connection media between network equipment, such as NICs and switches. NVMe-oF can transport data more efficiently between a target and an initiator than its predecessor iSCSI could. If you can use RDMA with NVMe-oF, you will get even more efficiency than you would by using NVMe-oF and TCP. NVMe-oF can use traditional fabric such as Ethernet, or it can use newer (and often faster) connection media such as InfiniBand and Fibre Channel.
Where LINBIT Enters the Picture
The LINBIT®-developed open source data replication software, DRBD®, has an RDMA module that can make DRBD’s synchronous replication over the network more efficient. More often than not, DRBD is used in hyperconverged clusters where storage is directly attached to compute nodes. This means that there is an application running on the same host as DRBD. By using RDMA, you could ensure that DRBD and the application are not competing for CPU time.
LINBIT developers introduced an RDMA transport kernel module for DRBD in 2014 on the DRBD 9.0 branch. The kernel module became open source with the 9.2.0 branch in 2022 and supports load balancing DRBD replication traffic.
The following sections give basic instructions for preparing a system for using RDMA with DRBD.
Installing RDMA on Red Hat Enterprise Linux
For Red Hat Enterprise Linux (RHEL) installations, enter the following RPM installation commands on all servers:
dnf -y install rdma-core
dnf -y install libibverbs-utils infiniband-diagsInstalling RDMA on Ubuntu Linux
To install RDMA in Ubuntu Linux, enter the following commands on all nodes:
apt -y install rdma-core
apt -y install infiniband-diags ibverbs-providers ibverbs-utilsListing RDMA Devices and Device Statuses
You can list the InfiniBand devices on your system by entering the ibv_devices command. You can show the status of InfiniBand devices on your system by entering the ibstat command.
Configuring DRBD to Use RDMA
After preparing your systems for RDMA use, to tell DRBD to use RDMA, set the transport option in the net section of your DRBD resource configuration, as follows:
resource <resource-name> {
net {
transport "rdma";
}
[...]
}You can further configure the RDMA transport in DRBD by specifying certain options and values. The DRBD User Guide and the drbd.conf-9.0 manual page (man drbd.conf-9.0) have more information about configuring the RDMA transport.
Conclusion
If you have reached the limitations of TCP in your deployments and are experiencing performance bottlenecks by using it, or if you require high-speed and low-latency network data transferring, then it might be worth exploring RDMA as an alternative. You can reach out to the LINBIT team if you have any questions about deploying RDMA for DRBD.


